
GPT-5.3-Codex をチーム開発に導入するための統制設計ガイド——任せる範囲と権限の決め方
GPT-5.3-Codexをチーム開発に組み込もうとしているチームにとって、怖いのはモデルの性能ではなく「運用で何が壊れるか」のほうではないでしょうか。
Codexが単なる補完ではなくCLIやツール実行を伴う作業者になった今、PoCが止まる原因として統制点の不在が挙げられることが少なくありません。よくある失敗パターンを挙げると:
- 逸脱変更:指示外のファイルを勝手に書き換える
- 破壊的コマンド:git reset --hard が承認なしで走る
- 依存関係の誤推定:存在しないパッケージを参照する
- コスト暴発:トークン消費が想定の数倍に膨らむ
- 品質ドリフト:モデル更新やコンパクションの蓄積により出力品質が緩やかに劣化し、昨日通ったテストが今日は落ちる
この記事では、何を任せて何を任せないかの判断軸と、実行中に人間が方向修正や中断を差し込むステアリング(steering)、長いやり取りの履歴を要約・圧縮してコンテキストウィンドウに収めるコンパクション(compaction)を前提にした運用設計の型を整理します。
記事の終わりには、導入チェックリストとエージェントの挙動を制約するルール群であるガードレールの雛形、回帰テスト用の基準入出力集であるゴールデンセットのテンプレートも載せています。
Codexは『補完ツール』ではなく『作業者』
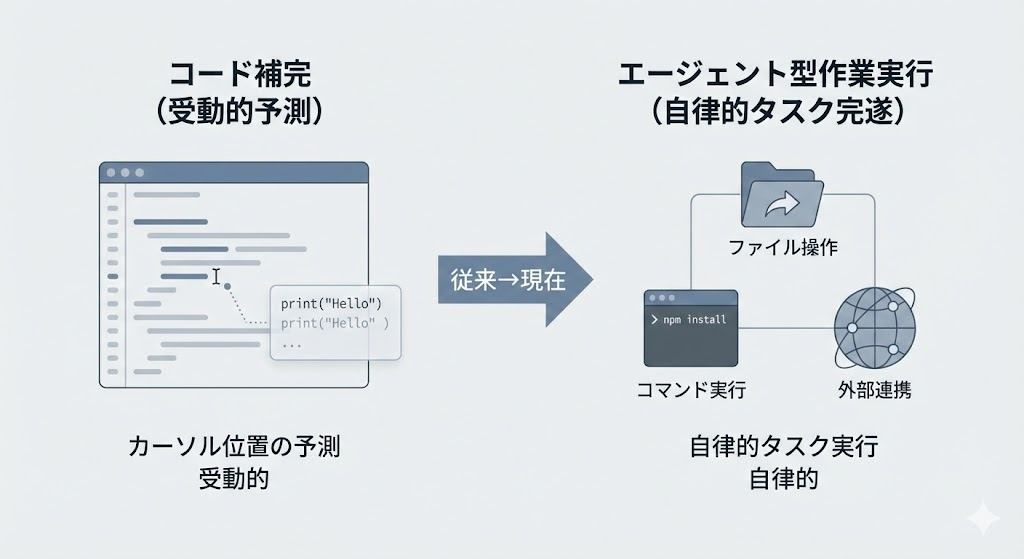
補完と作業実行の違い
従来のコード補完はカーソル位置の続きを予測する受動的な支援でした。一方、GPT-5.3-Codex はデバッグ・デプロイ・モニタリング・要件定義・ドキュメント作成・テスト・データ分析など、ソフトウェア開発ライフサイクル全体を支援する設計になっています。
モデル自体がコード生成だけでなく、ファイル操作・コマンド実行・外部ツール連携といった「作業の完遂」を前提に構築されているためです。GPT-5.3-Codexは前モデル比で25%高速化されたエージェント型コーディングモデルとのこと。
ただし作業者である以上、指示の曖昧さや権限設計の不備がそのまま事故につながりかねません。補完ツールの延長として導入すると、統制の抜け漏れが起きてしまうかもしれません。
Codexが実行できる作業の範囲(CLI・IDE・クラウド)
Codexの作業形態は大きく3つに分かれます。
- CLI — ローカル環境やCI上での自動化向け
- IDE統合 — エディタ内での対話的な作業向け
- クラウド実行 — 長時間タスクやサンドボックス検証向け
まずCLIでの小さなタスク自動化から始め、CI連携やクラウド実行へ段階的に広げていくとスムーズかもしれません。
たとえばCodex CLIでは以下のような機能が提供されています:
- モデル切替
- 画像入力
- ローカルコードレビュー
- 多エージェント並列実行
- Web検索
- クラウドタスク実行
- スクリプト呼び出し
- 外部ツール(MCP)連携
- 承認モード設定
各形態で使える機能や承認フローの粒度は異なります。提供状況やプランによる差異は公式ドキュメントで確認しておくと安心です。
導入で詰まる5つの失敗パターンと、その共通原因
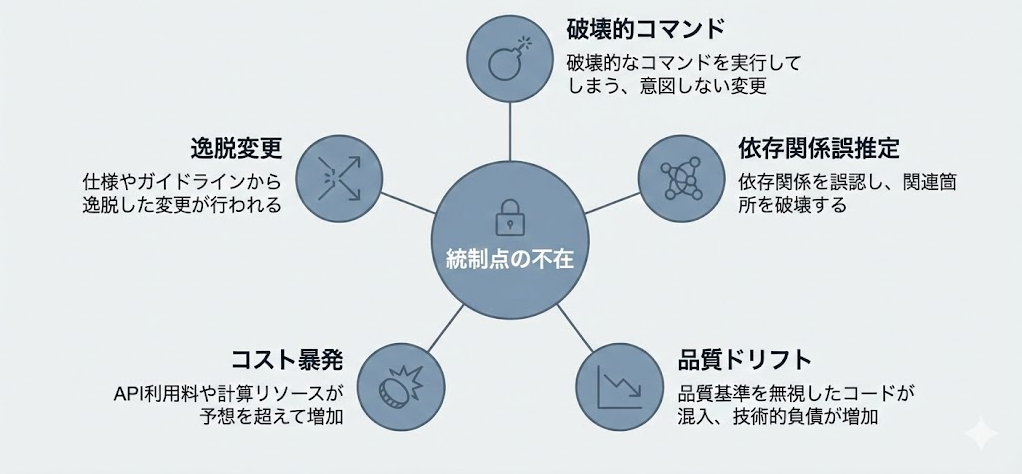
Codexの作業範囲と統合パターンを押さえたところで、次は導入プロジェクトが実際に止まる場面を見ていきます。原因は性能不足ではなく、品質ドリフトや変更管理の欠落であることが少なくありません。ここでは現場で繰り返し報告される5つの失敗パターンと、その底にある共通原因を整理します。
逸脱変更——指示外のファイルを勝手に書き換える
「READMEだけ直してほしかったのに、関連ファイルまで書き換えられていた」——こんな経験はないでしょうか。
エージェントはタスク達成を最優先に動きます。作業スコープが曖昧な指示を受��けると、モデルが「関連しそうなファイル」まで変更対象に含めてしまうことがあります。自然言語の指示には明示的な境界がないためです。変更対象のディレクトリやファイルパスをプロンプトで限定しないと、この逸脱は再現しやすくなります。
破壊的コマンド——git reset --hard が走る瞬間
エージェントがGit操作を含むタスクを実行する場面は珍しくありません。そのなかで、git reset --hard のような破壊的コマンドが意図せず実行されるリスクがあります。Codexでは、RLによる訓練とCLIの追加プロンプトで破壊的操作を避けるよう対策されていますが、「走らない保証」ではありません。
この仕組みはリスクを下げる工夫であり、環境やバージョンによって挙動が異なる可能性もあるため、自チームのサンドボックスで検証しておくのが安心です。
依存関係の誤推定——存在しないパッケージを参照する
モデルは学習データに含まれるパッケージ名を元に依存関係を推定しています。そのため、廃止済みや名称変更されたパッケージ、あるいは実在しないパッケージ名を package.json や requirements.txt に追記してしまうことがあります。��学習時点と現在のレジストリ状態にずれがあることが原因です。CIでの依存解決チェックがないと、ビルド失敗の原因が見えにくくなりがちです。
コスト・遅延の暴発——トークン消費が読めない
多くのLLM料金体系では、出力トークンが入力より高価に設定される傾向があります(倍率はモデルや時期によって変動します)。そのため、長時間タスクや反復実行で出力量が膨らむと、コストと遅延が一気に増加します。実際に、設計ツール構築タスクで25時間連続動作し約1,300万トークンを消費した報告もあります。
タスク単位の上限トークン数や中断条件を事前に決めていないと、こうしたコスト暴発に気づくのが遅れがちです。
品質ドリフト——昨日は通ったテストが今日は落ちる
モデルのアップデートやコンパクションはユーザーが明示的に制御できない場面があります。そのため、昨日通っていたテストが今日は落ちる——いわゆるデグレが起きることがあります。��品質ドリフトは緩やかに進行するため、発見が遅れがちです。モデル内部の重み更新やコンパクション時の情報欠落が出力に影響することが、その背景にあります。ゴールデンセットによる定期的な回帰テストがないと、劣化の検出が属人的な気づきに頼りがちになる点も押さえておきたいところです。
5つのパターンに共通する原因——統制点が決まっていない
これらのパターンに共通するのは「統制点の設計不在」です。以下の統制点がチームで合意されていないと、エージェントの挙動がどこで逸脱しても気づきにくくなります:
- 作業スコープ
- 承認フロー
- コスト上限
- 回帰テスト基準
コーディングエージェント運用では、従来のコードレビューだけではカバーしきれない制御ポイントが出てきます。統制点は一度決めて終わりではなく、運用しながら見直す前提で設計しておくとよいでしょう。
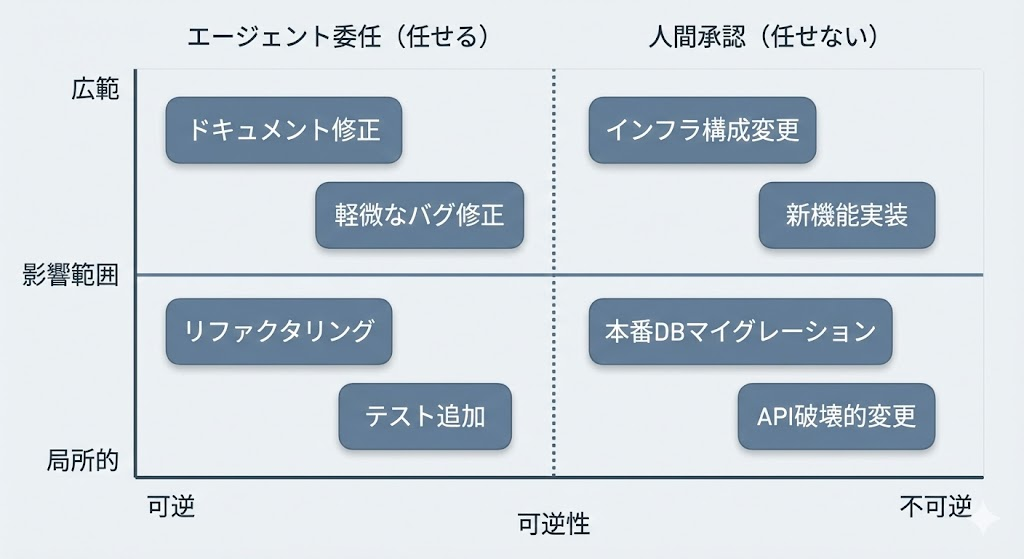
任せる/任せないの判断軸——責任分界と権限設計の型
失敗パターンの共通原因が「統制点の不在」にあるとすれば、次に考えたいのは「どこまでCodexに任せ、どこで人間�が判断を握るか」です。ここではその判断軸と、サンドボックスや承認フローを含む権限設計の型を整理します。
判断軸の考え方——影響範囲×可逆性で分類する
作業を任せるかどうかの判断は「影響範囲×可逆性」という2軸で考えると整理しやすくなります。影響範囲が広く不可逆な操作ほど人間の判断を残し、影響が局所的で可逆な操作はエージェントに委ねる、という分け方がスムーズです。
たとえば、単一ファイル内のリファクタリング(局所的・可逆)はCodexに任せやすい一方、本番DBのマイグレーション(広範・不可逆)は人間の承認が前提です。ここで気をつけたいのが、「可逆に見えて実は不可逆」な操作の存在です。外部APIへのPOSTなどが典型で、見落としてしまうかもしれません。判断に迷う操作は一段上の承認レベルに寄せておくのが安全です。
サンドボックスと承認モードの使い分け
Codexの権限設計では「作業段階ごとにどの承認モードを選ぶか」がポイントになります。Codexはデフォルトでネットワーク無効・ワークスペース内のみ書込可のサンドボックス環境で動作し、外部権限やネットワーク呼び出しにはユーザー承認を要求します。
Autoモード(--full-auto またはフラグなし)ではワークスペース内の編集・実行を自動で許可しつつ、外部アクセスは都度承認を求める形になっています。具体的には workspace-write + on-request という組み合わせです。read-onlyモードはコード解析やレビュー段階で有効です。
段階的に権限を広げていく形が進めやすいでしょう。たとえばPoC段階ではread-only → 開発作業ではAutoという流れです。なお、--yoloは承認とサンドボックスを両方バイパスするため、原則として使わないのが安全です。使う場合は、外部で隔離したコンテナやCI環境に限定することを強く推奨します。
禁止操作リストと最小権限の設計例
ガードレール設計の出発点は「何を禁止するか」を明示的にリスト化することです。最小権限の原則に基づき「デフォルトは禁止、必要なものだけ許可」の方向で設計するのが堅実です。
禁止操作の代表的な例としては、git reset --hard や rm -rf などの破壊的コマンド、外部ネットワークへの通信、.env やシークレットファイルへの参照があります。
まずチームで「絶対に自動実行させたくない操作」を洗い出し、それをCLI設定やCI側のpre-commitフックで強制する形が考えられます。禁止リストは網羅性よりも更新性が重要で、インシデントが起きるたびに追加・見直す運用を前提にしておくと、リストが実態から乖離しにくくなります。
責任分界をチームで合意する進め方
権限設計を属人化させないためには「合意プロセスの型」が鍵になります。禁止操作一覧と承認フローをドキュメント化し、チーム全員がレビュー・更新できる状態にしておくとよいでしょう。
まず禁止操作と承認モードの一覧をリポジトリ内のMarkdownに置き、PRレビューと同じフローで変更を管理します。加えて、「誰がどの範囲の承認権限を持つか」をREADMEやrunbookに明記し、オンボーディング時に共有する形がスムーズです。
責任分界の文書は作って終わりではなく、月次や四半期のふりかえりで実態とのズレを確認する運用も欠かせません。
ステアリング運用——介入タイミング・レビュー差し込み・作業ログの設計
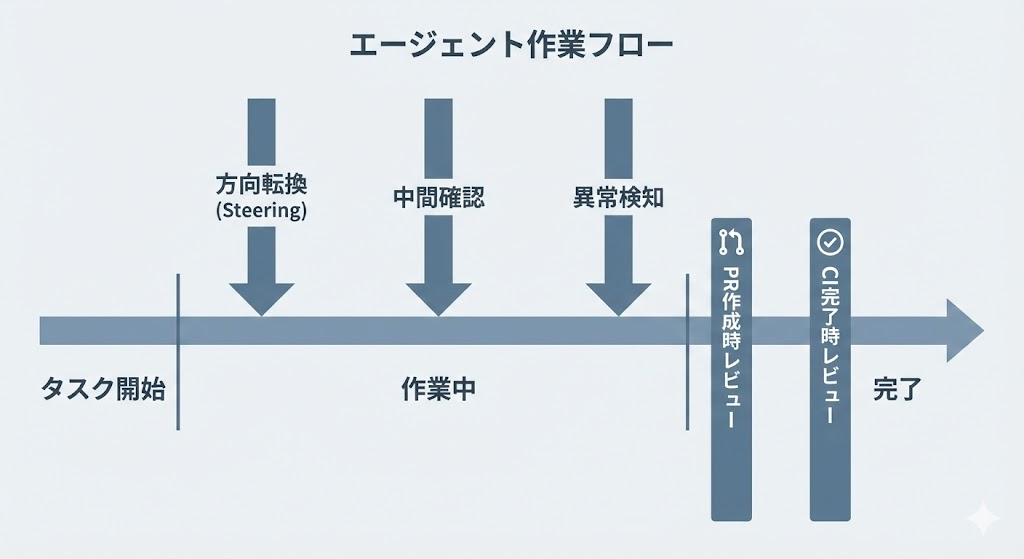
権限設計でサンドボックスや承認フローを整えても、エージェントが走り出したあとのステアリングが抜けていると、途中の方向ズレに気づけないまま作業が進んでしまいます。
ここでは「いつ・どこで介入し、何をログに残すか」を整理します。GPT-5.3-Codexはモデル動作中に随時ヒントや指示を与えられるインタラクティブなエージェントであり、この特性を活かすには介入の粒度を設計しておく必要があります。
ステアリングが必要になる3つのタイミング
ステアリング介入が効く場面は大きく3つに分けられます。いずれも「作業完了後」ではなく「途中」で差し込むことに価値があると言えるでしょう:
- 方向転換 — 要件変更やスコープの縮小が発生したとき、エージェントに即座に新しい方針を伝えないと、旧仕様のまま実装が進む。タスク指示を途中で差し替えられる環境が必要
- 中間確認 — ファイル数が一定数を超えた時点や、外部APIとの接続直前など、影響範囲が広がる手前で差分を確認する。変更が大きくなってからのロールバックはコストが高い
- 異常検知 — CI失敗の連続、想定外のファイル変更、トークン消費の急増といったシグナルが出たら、作業を止めて原因を確認する。異常の閾値は事前に決めておかないと、気づいた時点では手遅れになりがち
レビュー差し込み点の設計——PRとCIへの組み込み方
PR運用とCIパイプラインのどこにレビューポイントを置くかがポイントになります。レビュー差し込み点は「PR作成時」と「CI完了時」の2箇所を軸にします。
PR作成時には、エージェントが変更したファイル一覧と差分サマリを人間がレビューします。エージェントにPR作成まで自動実行させる場合でも、マージ権限は人間に残す運用が安全です。
CI完了時には、テスト結果とlint結果を確認し、品質ドリフトの兆候がないかを見ます。CIが通ったからといってレビューを省略すると、テストカバレッジ外の変更を見逃しやすくなります。
作業ログの残し方と監査性の確保
「何が行われたかを後から追跡できるか」が監査性の核心です。進捗や意思決定をDocumentationファイルに記録しておくと、途中離席後でも作業経緯を追跡できます。
ログは2種類に分けて残すのが整理しやすい形です:
- 進捗ログ — エージェントが自動出力するタスク完了/失敗の記録
- 意思決定ログ — 人間がステアリング介入した理由と変更内容の記録
エージェントの作業指示にログ出力先のファイルパスを含めておき、各ステップの完了時に追記させます。加えて、OpenAIの監査ログAPIを使うと、APIキーの発行や削除、プロジェクト管理の変更などを不変な監査ログとして取得でき、コンプライアンス管理に活用できます。
ログの粒度が細かすぎるとノイズになり、粗すぎると追跡不能になります。「1タスク完了ごとに1エントリ」程度がちょうどよいバランスかもしれません。
ステアリングの過介入を避けるコツ
介入頻度を上げすぎるとエージェントの効率が落ちてしまいます。このバランスをどう取るかがポイントです。
介入は「イベント駆動」にするとうまくいきやすいです。時間ベース(5分ごとに確認)ではなく、異常シグナルやマイルストーン到達をトリガーにします。正常に動いている間に割り込んでも、コンテキスト切り替えコストは大きくなりますが、品質ドリフトの防止にはそこまで大きく貢献するものではないかもしれません。
一方で、コンパクションが進むとエージェントの文脈が圧縮されるため、長時間タスクでは「放置しすぎ」にも注意が必要です。タスク規模に応じて中間確認の間隔を事前に決めておくとバランスが取りやすいでしょう。
コンパクション設計——要約ドリフトを防ぎ、決定事項を失わないために
ステアリングで介入タイミングとログの設計を固めたら、もうひとつの運用課題であるコンパクションに進みます。ここでは「長時間タスクで文脈が圧縮されるとき、何が失われ、どう防ぐか」を整理します。
コンパクションの仕組み——なぜ長時間タスクで必要になるか
なぜエージェントは会話履歴を圧縮するのでしょうか?結論から言えば、コンテキストウィンドウには上限があり、長時間の作業ではトークン量がその上限を超えるためです。
GPT-5.3-Codexは会話履歴を要約・圧縮するコンパクション機能を備えており、長い対話でも有効な文脈を維持できるとされています。外部評価では10万トークンごとにコンパクションをトリガーする設定が使われた報告がありますが、これは評価用の設定であり、実際�の頻度は運用や設定次第で変わります。
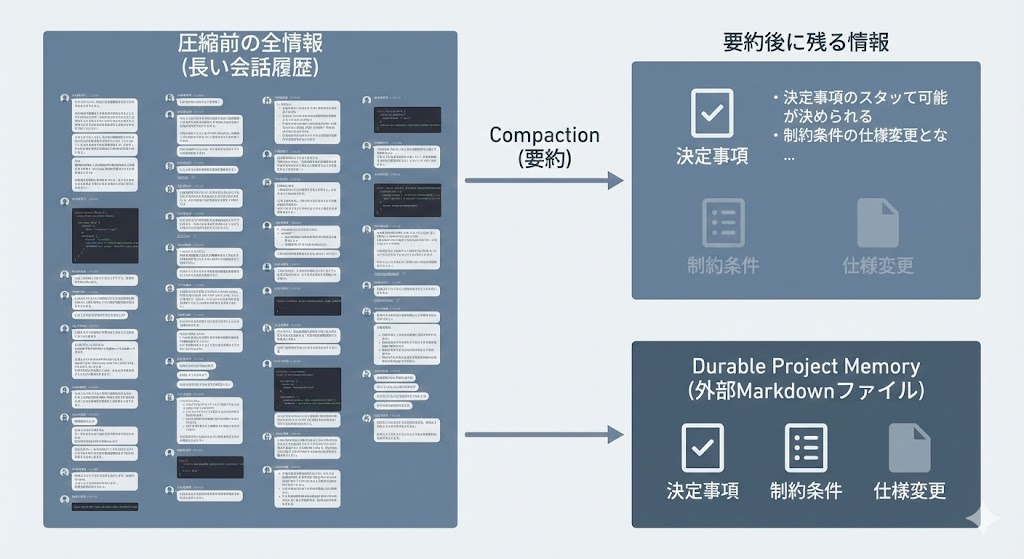
ただし、この圧縮は「全情報の保持」ではなく「要約による近似」です。要約である以上、情報の欠落は構造的に避けられません。
要約ドリフトの具体例——決定事項が消える・制約が薄まる
消えやすいのは「初期に決めた制約条件」と「途中で合意した仕様変更」です。要約は頻出パターンを残し低頻度の情報を落とす傾向があります。
たとえば「本番DBへの直接書き込み禁止」という制約が、作業が進むにつれて要約から脱落し、エージェントが制約を認識しないまま操作を試みる——というパターンが考えられます。制約条件は会話の冒頭で1回だけ言及されることが多く、要約の優先度が下がりやすいためです。
保持すべき情報の設計——Durable Project Memoryの活用
仕様・決定事項・制約をMarkdownファイルとして外部に永続化し、エージェントが各セッションで参照するDurable Project Memoryという構造が有効です。
Durable Project Memoryでは、プロジェクトルートに DECISIONS.md や CONSTRAINTS.md のようなファイルを置き、エージェントのシステムプロンプトで「作業開始時に必ず読み込む」と指定します。ただし、このファイル自体が肥大化すると読み込みトークンを圧迫するため、定期的な整理が必要です。
セッション分割と状態引き継ぎの実践パターン
長時間タスクでコンパクションによる情報欠落を根本的に減らす手段として「セッションを意図的に分割する」方法があります。1セッションの作業量を制限し、セッション終了時に状態をコミットする運用が安定しやすいです。
セッション終了前に進捗ログ(完了タスク・未完了タスク・次にやること)をMarkdownに書き出し、gitコミットしておきます。次セッション開始時にはそのログとDurable Project Memoryを読み込むことで、コンパクションに依存しない状態引き継ぎが成立します。
セッション分割の粒度が細かすぎると立ち上げコストが増えるため、環境に応じた調整が必要です。
コスト・遅延・品質を測る——運用指標の決め方
ステアリングとコンパクションで運用の型が見えてきたら、次はそれを数値で検証できる状態にしておきましょう。Codex運用のコスト・遅延・品質について、追跡すべき指標と、遅延やエラー率などサービス品質の目標値を定める「サービスレベル目標(SLO)」のしきい値の決め方を整理します。
追跡すべき運用指標の全体像
運用設計を始める前に、「何を測れば運用が回っているといえるか?」を決めておくと�スムーズです。追跡したい指標は次の5つです:
- タスク失敗率 — エージェントが完了できなかった割合。品質低下の直接シグナル
- 再実行率 — 人間がやり直した割合。自動化の実効性を示す
- 遅延 — 平均レスポンスと95パーセンタイル。体感とサービスレベル目標判定の軸
- コスト/タスク — 1タスクあたりのトークン費用。予算管理の基本
- 改変範囲 — 変更ファイル数・行数。逸脱変更の早期検知に有効
これらは単体で見るより組み合わせて傾向を追う方が有効です。たとえば失敗率が低くても改変範囲が急拡大していれば、逸脱変更の兆候と考えられます。
コスト設計——effort設定・キャッシュ・バッチの使い所
トークン費用を抑えるには、出力長の制御が鍵になります。多くのLLM料金体系では出力トークンが入力より高価に設定される傾向があるため(倍率はモデルや時期によって変動)、次の手段が有効です。
- effort設定:GPT-5.3-Codexは
low〜xhighの4段階��をサポート。定型的なリネームはlow、設計判断を伴うリファクタリングはhigh以上のように使い分ける - キャッシュ(API利用時):同一プロンプトの繰り返し実行で有効。CIの定期実行との相性が良い
- バッチ(API利用時):即時性が不要なタスク(夜間の一括レビューなど)で有効。APIは近日安全に有効化予定と発表されており、具体的な提供形態は公式ドキュメントで確認
遅延設計——TTFTとストリーミング、中断条件の決め方
遅延の代表指標であるTTFT(Time to First Token: 最初のトークンが返るまでの時間)を軸に、どこまで許容しどこで打ち切るかを決める必要があります。
ストリーミングを有効にするとTTFTの体感は改善しますが、総処理時間が短くなるとは限らない点に注意が必要です。中断条件の設計では、タイムアウト(例: 1タスク5分)とトークン上限(例: 出力32,000トークン)の2軸で打ち切りラインを設定するのが一般的です。環境やタスク特性で適正値は変わるため、最初は緩めに設定し、実測データを見て締めていく進め方��がスムーズです。
サービスレベル目標とアラートの設計例
「しきい値をいくつにするか?」が最も悩む点です。初期は実測ベースラインの1.5〜2倍程度をしきい値にし、運用データが溜まったら絞る方針が現実的です。
サービスレベル目標の例を挙げます。
- 遅延目標:95パーセンタイルのTTFTがN秒以内
- コスト目標:1タスクあたりの費用がX円以内
- エラー率目標:タスク失敗率がY%以下
アラートは、しきい値超過が連続M回で通知する形にすると、一時的なスパイクでの誤報を減らせます。数値自体はチームの要件や予算に依存するため、他社事例をそのまま転用するのではなく、自チームの実測から導くとよいでしょう。
回帰テストとガードレール——壊れたことに気づける仕組みの作り方
サービスレベル目標やコスト指標で異常を検知できても、「出力の中身が壊れた」ことに気づく仕組みがなければ品質劣化は静かに進みます。ここでは回帰テストとガードレールという2つの検知レイヤーで、ゴールデンセットを軸にした�品質防御の設計を扱います。
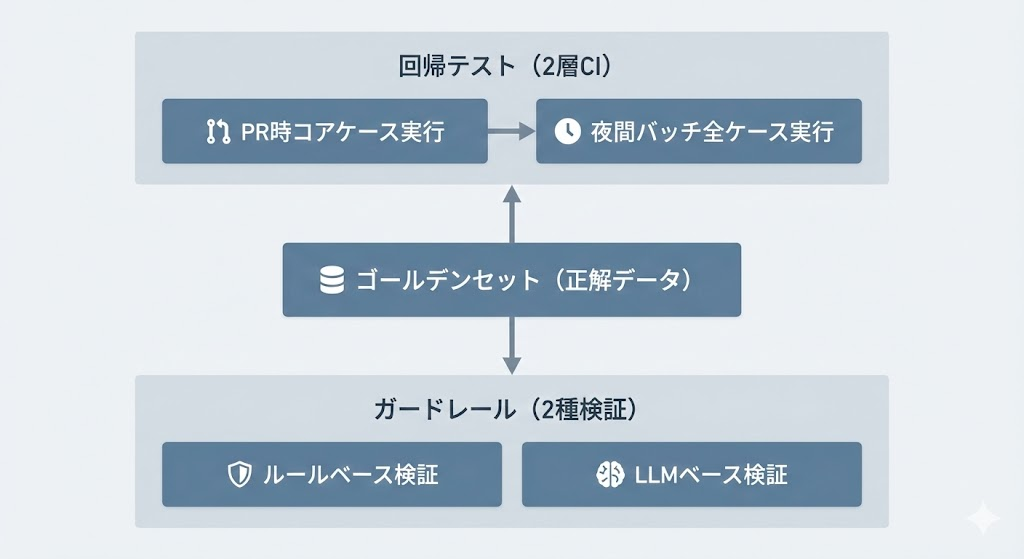
ゴールデンセットの作り方——5件から始める基本の構成
どんなテストケースを用意すればよいのでしょうか。本番ログから代表的な失敗パターンを5件程度抜き出した小規模なゴールデンセットから始めるのが現実的です。
直近1〜2週間の本番ログから「禁止回答を返した」「根拠なしで断定した」「フォーマットが崩れた」といった失敗事例を抽出し、入力と期待出力のペアにします。最初から網羅性を狙うと運用が回らなくなりがちなので、まず5件で開始し、PRゲート用に10〜20件へ拡張していく流れが安定します。ケースは増やせますが、減らすのは心理的に難しいため、小さく始めて徐々に拡張するのがポイントです。
CIへの組み込み——2層テスト構成(PR時+夜間)の設計
「回帰テストをCIのどこで回すか」が次の設計判断です。PR時と夜間/週次の2層に分ける構成が運用負荷と検出精度のバランスを取りやすいでしょう。
PR時には品質に直結するコアケース(10〜20件程度)だけを実行し、失敗すればビルドを止めます。全ケースをPR時に回すとフィードバックが遅くなり、開発者がテストを迂回する動機を生みがちです。全評価ケースは夜間や週次のバッチで実行し、既存の動作品質が新しい変更によって低下していないか(いわゆるデグレ防止)を検出する役割を持たせます。
差分レビューと非決定性への向き合い方
「同じ入力なのに出力が毎回違う」という非決定性が、回帰テストの判定を難しくします。LLMの出力は温度パラメータやサンプリングの影響で揺れるため、文字列完全一致での判定は現実的ではありません。
対処の方向性は2つあります:
- 意味的な一致判定 — 別のLLMや埋め込みベクトルで類似度を測る
- 正規化ルールの適用 — 比較前にテキストを正規化する
日本語特有の問題として、全角/半角の揺れ、「〜です」「〜である」の文体差、句読点の種類(,。vs、。)などがあるため、比較前に正規化ポリシーを決めておくとノイズが減ります。
ただし、正規化しすぎると本来検出すべき差異まで潰してしまうので、「何を同一視し、何を差異として扱うか」をチームで明文化しておくとよいでしょう。
ガードレール設計——入出力の検証レイヤーとセキュリティポリシー
「出力の品質」だけでなく「入��出力の安全性」を担保するのがガードレールの役割です。
ガードレールはLLMベースとルールベースを組み合わせた複数層で構成するのが効果的で、次のような検証を組み合わせます。
- ルールベース:禁止ワードのフィルタ、出力フォーマットのスキーマ検証、外部URL参照の制限など
- LLMベース:出力が指示の範囲内かを別モデルで判定するモデレーション層
Web検索機能を使う場合は、Codex CLIが既定でキャッシュ(インデックス)結果を返す仕様になっている点も押さえておきたいところです。ライブ検索に切り替えるとプロンプトインジェクションの攻撃面が広がるため、原則キャッシュ+ドメイン制限の組み合わせで運用するのが安全です。
セキュリティ面では、System Cardに記載されたリスク分類を参照し、自社の環境でどのリスクが該当するかを洗い出すのが出発点です。社内ポリシー雛形は「禁止操作」「承認が必要な操作」「ログ必須の操作」の3分類で整理すると、関係者間の認識が揃いやすくなります。
おまけ:導入チェックリスト・ガードレール例・回帰テストテンプレート
最後におまけとして、導入時に確認すべき項目とガードレールの雛形を残します。そのまま適用するよりは、環境やチーム構成など必要に応じて調整するのが良いかもしれません。
導入チェックリスト
意思決定・責任分界
- 任せる作業と任せない作業の分類を文書化したか
- 禁止操作リスト(破壊的コマンド、外部通信等)を定義したか
- 上記を関係者間で合意し、ドキュメントとして共有したか
権限・セキュリティ
- サンドボックス/承認モードの使い分けを決めたか
- 最小権限の設計と秘密情報へのアクセス制限を設定したか
- System Cardのリスク分類を自社環境に照らして確認したか
- ガードレール(入出力検証層)を実装したか
運用・介入設計
- ステアリングの介入タイミングとレビュー差し込み点を決めたか
- コンパクション時に保持すべき情報(決定事項・制約)を定義したか
- 作業ログの保存先と監査フローを整備したか
品質・コスト管理
- コスト/遅延のサービスレベル目標とアラート閾値を設定したか
- ゴールデンセット(5件以上)を作成したか
- CIに回帰テスト(PR時+夜間の2層)を組み込んだか
- 差分レビューの正規化ポリシーを決めたか
ガードレール雛形
- 禁止操作: git reset --hard、本番DBへの直接書き込み、外部APIへの未承認リクエスト
- 承認必須操作: 依存パッケージの追加/削除、インフラ構成の変更、秘密情報を含むファイルの参照
- ログ必須操作: ファイルの作成/変更/削除、コマンド実行履歴、外部通信の発生
回帰テストテンプレート
各ケースは「入力・期待出力・判定基準・優先度」の4列で管理します。判定基準は「完全一致」「意味的一致(例: 類似度0.85以上。閾値は手元のデータで校正)」「フォーマット一致」などから選択します。優先度はPR時に実行するコアケース(P0)と夜間バッチで実行する拡張ケース(P1)に分け、P0は10〜20件を目安にします。
よくある質問
- ステアリングとコンパクションはそれぞれ何をする機能ですか?
- ステアリングはエージェントの実行中に人間が方向修正や中断を差し込む操作のことで、「ステアリング運用」のセクションで詳しく扱っています。コンパクションは長いやり取りの履歴を要約・圧縮してコンテキストウィンドウに収める処理で、「コンパクション設計」のセクションで仕組みと対策を整理しています。
- Codex CLIの承認モードはどう使い分ければいいですか?
- 作業段階に応じて段階的に権限を広げていく形がスムーズです。PoC段階ではread-only、開発作業ではAuto、CI自動化で承認解除という流れが良いでしょう。詳細は「サンドボックスと承認モードの使い分け」で整理しています。
- ゴールデンセットは何件くらいから始めればいいですか?
- 5件程度から始めるのがおすすめです。本番ログから代表的な失敗パターンを抽出し、PRゲート用に10〜20件へ拡張していく流れが安定します。「ゴールデンセットの作り方」で手順を整理しています。
- --yoloオプションを使っても安全ですか?
- --yoloは承認とサンドボックスを両方バイパスするため、原則として使わないのが安全です。使う場合は、外部で隔離したコンテナやCI環境に限定することを強く推奨します。通常の開発では、多くの場合Autoモード(--full-auto)で対応できます。
- コンパクションで要約されると重要な決定事項が消えませんか?
- 消えることがあります。要約は頻出パターンを残し低頻度の情報を落とす傾向があるため、初期に決めた制約条件が脱落しやすいです。対策として、仕様・決定事項・制約をMarkdownファイル(Durable Project Memory)として外部に永続化し、各セッションで参照する構造が有効です。詳細は「コンパクション設計」で整理しています。
- Codexの出力コードに脆弱性が混入するリスクにはどう対処しますか?
- ガードレールとして、LLMベースとルールベースを組み合わせた複数層で検証する構成が効果的です。ルールベースでは禁止ワードのフィルタやスキーマ検証、LLMベースでは出力が指示範囲内かを別モデルで判定します。「ガードレール設計」で構成例を整理しています。
- CIに回帰テストを組み込むとコストはどのくらい増えますか?
- コスト増はケース数とテスト頻度に依存しますが、PR時のコアケースを10〜20件に絞り、全ケースは夜間バッチで回す2層構成にすることで、フィードバック速度とコストのバランスを取りやすくなり��ます。具体的な数値は実際の環境で測定するのが確実です。
最後に
コーディングエージェント運用で最初に考えたいのは「何を自動化するか」ではなく「どこに統制点を置くか」です。導入は次の4ステップで進めると手戻りが少なくなります。
- 統制点の設計 — 禁止操作リスト・承認フロー・サンドボックス境界を先に決める。ここが曖昧なまま作業を任せると、逸脱変更や破壊的コマンドの事故が起きやすくなります。
- 小範囲で導入 — 影響範囲が限定的で可逆性の高いタスク(テスト生成、ドキュメント更新など)から始めると、チーム内の運用感覚が掴みやすくなります。
- 回帰テストで確認 — ゴールデンセットをCI に組み込み、品質ドリフトが検知できる状態を作ります。5件程度の小さな構成でも、デグレ防止の安全網として機能します。
- 範囲拡大 — 統制点と検知の仕組みが回り始めてから、対象タスクやリポジトリを段階的に広げていきます。
ステップ1を飛ばして2から始めると、問題が起きたときの切り分けが難しくなりがちです。まずは止め方を決めると安心です。
PASHでは、短時間で現状を把握したい方向けのスポット相談も行っています。ぜひご利用ください。
更新履歴(最終更新: 2026年2月26日)
- 初回公開
著者プロフィール
大崎 一徳 / エンジニア
中小企業向けに、AI導入・業務自動化・ツール開発を支援しています。 PoC から本番運用まで一貫して伴走し、「現場で使われ続ける仕組み」をつくることを大切にしています。
Udacity Deep Learning Nanodegree 修了
日本ディープラーニング協会(JDLA)主催 第1回ハッカソン GPU Eater賞受賞(チーム ニューラルポケット)



