
社内AIチャット・RAGが使われない7つの原因と改善ステップ
社内AIチャットやRAG(検索拡張生成)の本当の競合は、ChatGPTでも社内検索でもありません。 「詳しい人に聞く」です。
AIに聞くより、経理や人事の詳しい人にSlackで聞いた方が早い。そう感じられた瞬間、そのRAGは使われなくなります。PoCでは好感触だったのに本番で利用率が伸びない場合、まず見るべきなのは「回答できるか」ではなく、「信頼できる回答に、人に聞くより早く到��達できるか」です。
社内RAGが使われる条件は、シンプルです。
信頼できる回答に到達する時間 < 既存手段で解決する時間
ここでいう既存手段とは、人に聞く・自分で探す・担当者に確認するなど、利用者が普段使っている最短ルートです。AIの回答を得て確認するまでの手間がこれを上回るなら、利用者にとってそのRAGは合理的ではありません。
この時間が逆転している質問が多いなら、モデル変更の前に、対象業務・根拠提示・導線・運用を見直す必要があります。
原因の多くは、モデル性能だけではなく、知識データの整備不足・回答への信頼欠如・業務導線とのズレ・運用サイクルの不在という4系統に収束しがちです。そしてこの切り分けは、ログ基盤がない環境でも代表質問セットを使ったスポット評価で進められます。
この記事では、7つの原因パターンを「症状→確認→改善ステップ」の流れで整理し、改善の進め方を紹介します。
- RAGで解くべき業務か、FAQ・検索・ワークフローで足りる業務かを分ける
- 人に聞くより早く信頼できる回答に到達できているかを測る
- 代表質問20問を作り、RAGの弱点を洗い出す
- 20問×上位3根拠で「検索が悪いのか・生成が悪いのか」を切り分ける
- 危険質問10問で「答えない設計」を点検する
- 最初の1か月、2か月目、3か月目の順で改善を進める
「ログもないし、どこが悪いのか検証方法がまったく見えない」という状態についても対応できるように整理します。
そもそもRAGで解くべき業務かを確認する
RAGを改善する前に、その業務が本当にRAGで解くべきものかを確認します。単純なFAQで足りるもの、社内検索で文書を見つければ済むもの、最終的に担当者の承認が必須になるものは、RAG化しても定着しにくい場合があります。
RAGが向いているのは、複数の文書を横断して確認する必要があり、利用者が毎回人に聞いたり探したりしている業務です。たとえば、就業規則・申請手順・例外条件・関連フォームをまたいで確認するような質問は、RAGの価値が出やすい領域です。
まず「AI回答が必要な業務」と「検索・FAQ・ワークフロー整備で足りる業務」を分けると、改善対象を絞れます。存在すべきでないRAGを最適化するより、使われる可能性が高い業務に絞って評価した方が、改善の効果も見えやすくなります。
RAGが使われない原因は、モデル性能だけではない
RAGが使われない原因を「モデルの精度が低いから」と片付けたくなりますが、実際には業務用途の不明瞭さや運用設計の欠如が主因であり、AIモデルの精度よりデータ整理や運用設計が課題という指摘もあります。RAGの定着を阻む壁は、モデルを入れ替えるだけでは越えられないケースがほとんどです。
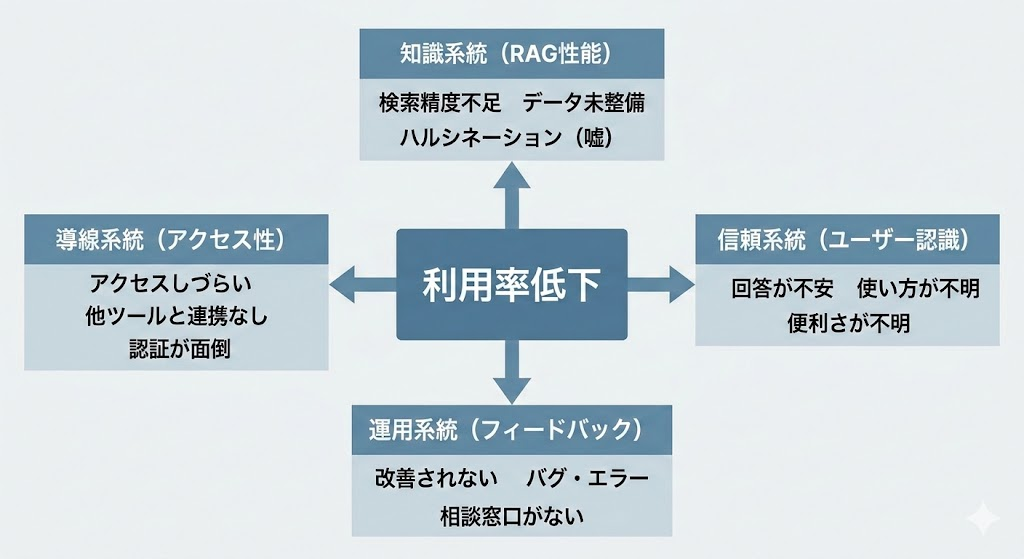
では、モデル以外のどこに原因があるのでしょうか。整理すると、4つの系統に収束します。
知識・信頼・導線・運用——RAGが使われなくなる4系統
4つの系統それぞれが、どのような問題を含んでいるのかを見ていきます。
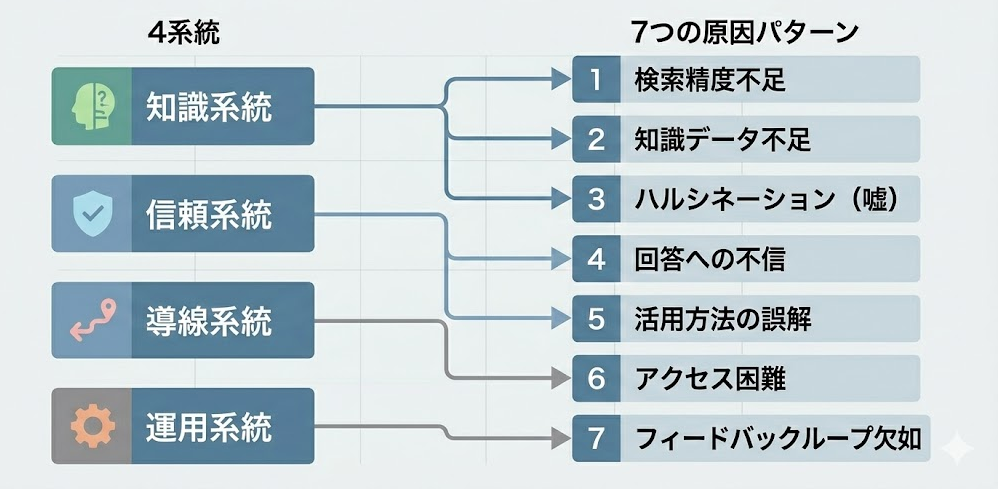
知識系統は、AIが参照するデータそのものに起因する問題です。対象業務が曖昧で用途が定まらなかったり、知識データが古い・足りない・整理されていないために回答がずれたり、検索がそもそも当たらなかったりする——これらはすべて知識系統に分類できます。次セクションのパターン①〜③がここに対応します。
信頼系統は、回答の信用やセキュリティに関わる問題です。根拠が示されず「本当に合っているのか」と疑われる状態や、機密情報の漏洩を心配して利用をためらう状態が該当します。パターン④・⑤がこの系統です。
導線系統は、業務フローとの接続に関わる問題です。現場では「Slackと連携できていない」のように、UIやアクセス経路が日常業務に溶け込んでいないために使われないケースがあります。パターン⑥がこの系統にあたります。
運用系統は、改善サイクルの不在に関わる問題です。導入時に整備しても、担当者がいない・フィードバックが回らないまま放置されると、データもルールも陳腐化していきます。パターン⑦がここに該当します。生成AI導入では、モデル性能だけでなく、業務フローへの適合・継続的な学習・運用面の課題が成果を左右するという指摘もあります。
4系統のどこにボトルネックがあるかで、打ち手はまったく変わります。次セクションでは、各系統に紐づく7つの原因パターンを掘り下げます。
7つの原因パターン——症状・確認・改善ステップ
ここからは7つの原因パターンを、それぞれ症状・確認方法・改善ステップの順に見ていきます。自社の状況がどの系統に近いかを意識しながら読むと、着手点を絞りやすくなります。
パターン①:対象業務が曖昧で「何に使えばいいか分からない」
症状: 経費精算の何を聞けばいいのか分からず、結局チャットを開かない。「どこで使えばいいかわからない」という声が上がり、利用が伸びない。
ログなし確認: (1) 部署ごとに実際に投げた質問を3〜5件ヒアリングする → (2) 用途が「○○業務の△△確認」のように言語化できるか確認する。
改善ステップ: 対象業務を1つに絞り、想定質問を10件ほど言語化する。
落とし穴: 「全社で使える」を目指すと用途が曖昧になり、結局誰も使わない。
パターン②:知識データが古い・足りない・整理されていない
症状: 最新版の就業規則を入れたはずなのに、廃止済みの在宅勤務ルールを返してしまう。古い規程や手順が回答に混ざる。
ログなし確認: (1) 代表質問5件を投げる → (2) 回答に引用された文書の更新日を目視で確認する。
改善ステップ: 更新頻度の高い文書を特定し、四半期ごとの見直しルールを設ける。
落とし穴: 「全文書を最新化」は現実的でない。問い合わせ頻度の高い領域から優先する。
パターン③:検索が当たらない
症状: 「有給休暇」と聞いたのに正しい文書が出ず、「年次有給休暇」と入力しないとヒットしない。正しい文書が登録されているのに、回答に反映されない。
ログなし確認: (1) 同じ意味の質問を言い換えて投げる(例:「有給」→「年次休暇」) → (2) 検索結果の差から表記ゆれの影響を確認する。
改善ステップ: まず表記ゆれ・同義語を確認し、それでも改善�しない場合は、チャンクサイズ、ドキュメントパース、メタデータ、ハイブリッド検索、リランキングの順に見直す。検索精度はチャンク選択、コンテキスト欠落、意味的類似性の限界、表現ゆれなどの影響を受けるため、同義語だけで解決しないケースも多い。
落とし穴: いきなり複雑なAdvanced RAGへ進むと原因が見えにくくなる。まず代表質問で、表記ゆれ、チャンク、メタデータのどこに失敗が集中しているかを確認する。
パターン④:回答に根拠がなく信用されない
症状: 回答はそれらしいけれど、どの規程のどこを見れば確認できるのか分からない。出典(どの文書のどこを参照したか)が示されず、「本当に合っているのか」と疑わしい。
ログなし確認: (1) 代表質問を5件投げる → (2) 回答に根拠となる文書名・ページ番号が表示されるか確認する。
改善ステップ: 参照元のファイル名とページ番号を表示する。
落とし穴: 根拠を出しても文書名が暗号的だと意味がない。命名規則の整理も併せて検討する。
パターン⑤:セキュリティ不安で使うのをためらう
症状: この情報をAIに入力してよいのか分からず、本番データでは試せない。「機密が漏れるのでは」という不安から、そもそも使われていない。
ログなし確認: (1) 利用をためらっている人に理由をヒアリングする → (2) 懸念が技術的(データ保存先・外部送信)か心理的(漠然とした不安)かを分類する。
改善ステップ: データの流れを1枚の図にまとめ、回答対象外の領域を明示する。
落とし穴: 技術的に安全でも「説明されていない」だけで不安は残る。周知が改善の半分を占める。
パターン⑥:UIや導線が業務フローに合っていない
症状: 専用ポータルを探すより、Slackで担当者に聞いた方が早いと感じられている。専用画面を開く手間が大きく、日常業務の流れに溶け込んでいない。
ログなし確認: (1) 利用者の業務動線を観察する → (2) AIチャットにたどり着くまでのクリック数を数える。
改善ステップ: 既存チャット(Slack・Teamsなど)への組み込み、または導線を整備する。
落とし穴: 導線を増やしすぎると「どこから使うのが正解か」が分からなくなる。入口は1つに絞る。
パターン⑦:運用担当がいない・改善サイクルが回っていない
症状: 先月指摘した誤回答が直ったのか分からず、また同じ質問で失敗する。フィード�バックを拾う人がおらず、品質が放置されたまま利用が減っていく。
ログなし確認: (1) 最後のデータ更新日を確認する → (2) 改善要望の受け口(フォーム・チャンネル)が存在するか確認する。
改善ステップ: 月1回の振り返り定例と、担当者1名のアサインを設定する。
落とし穴: 「運用担当」を曖昧にすると誰も動かない。名前と権限を明示する。
原因が複数の場合——まず着手するパターンの選び方
実際には複数のパターンが重なっているケースが多いです。そんなときは、パターン①(用途定義)と②(データ品質)から先に押さえると、他のパターンの影響も見えやすくなります。
どこから手をつけるか迷ったら、代表質問を5件ほど試して「検索が当たらないのか・回答の質が低いのか・そもそも使われていないのか」を切り分けると、判断が進みやすくなります。
ログがなくても切り分けられる理由と代表質問セットの使い方
RAGが使われなくなる7パターンの分類について切り分けを進めようとすると「ログ基盤がないと原因を特定できないのでは?」という意見が出てくるかもしれません。ただ、代表質問セットを使ったスポット評価で、ボトルネッ��クの推定は十分に可能です。
なぜログなしでも切り分けが可能なのか
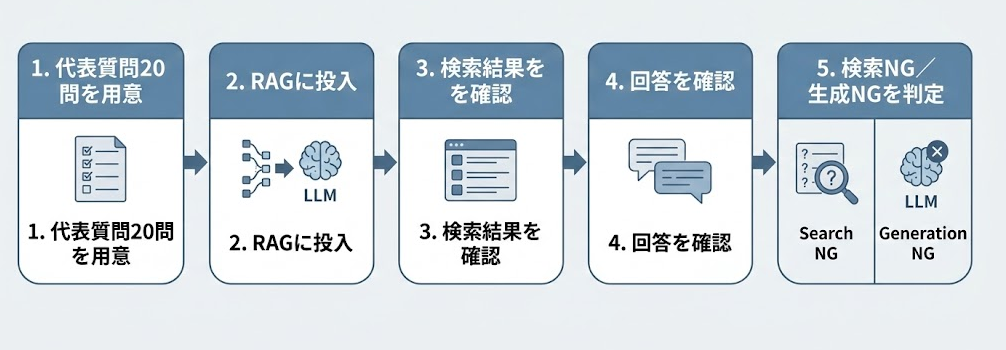
ログなしでも切り分けられる理由はシンプルで、RAGの出力品質は「検索が当たったか」と「生成が正しかったか」の2段階に分かれるため、少数の質問でも各段階の成否を目視で判定できるからです。20〜50件ほどの質問回答ペアを用意し、検索についたか・生成が合っていたかで仕分けるだけでも、どの段階にボトルネックがあるかは見えてきます。
ただし、スポット評価はあくまで傾向の把握であり、網羅的な品質保証とは異なります。「全体の正答率」よりも「どの系統で失敗が集中しているか」を掴むことが目的です。
代表質問20問の選び方と評価の進め方
代表質問20問をどう選ぶかについて、選定の観点は大きく3つあります。
- 業務領域のカバー:問い合わせが多い領域(就業規則、経費精算、製品仕様など)から偏りなく選ぶ
- 難易度の分散:単純な事実確認、複数文書の横断、判断が必要な質問を混ぜる
- 質問タイプの多様性:「〜とは何か」「〜の手順は」「〜と〜の違いは」など形式を変える
評価の進め方としては、各質問について「検索結果に正解の根拠が含まれていたか」と「生成された回答が正確だったか」を分けて判定します。検索が外れていれば検索側の改善が先、検索は当たっているのに回答が不正確なら生成側の調整が先、という切り分けができます。
問数は20問が目安ですが、組織規模や業務範囲によっては50問以上に増やすケースもあります。更新前後でA/B比較し、正答率や引用一致率を測定すると、改善の効果も追跡しやすくなります。
ログが取れる場合に残しておきたい項目の補足
「今はログ基盤がないけれど、後から整備するかもしれない」という状況であれば、後追いでも残しておきたい項目があります。
- ユーザーの入力クエリ(匿名化済み)
- 検索で返ったドキュメントIDと順位
- 生成された回答のスナップショット
- ユーザーのフィードバック(「役に立った / 立たなかった」程度でも十分)
この4項目があれば、スポット評価の結果と突き合わせて「実際の利用でも同じ傾向が出ているか」を検証できます。ログ基盤の構築が難しい場合でも、スプレッドシートに手動で記録する運用から始められるため、完璧な基盤を待つ必要はありません。
検索品質と回答品質——見落としやすい落とし穴
評価を始めると、次に「回答がおかしいのはどこの問題か」という疑問が出てきます。検索(retrieval)の段階で的外れな根拠を拾っているのか、生成(generation)の段階で根拠を正しく要約できていないのかで、打ち手はまったく変わります。
検索と生成を分けて評価する理由
「回答の質が低い原因はどこにあるのか」を特定するには、検索と生成を分けて観察する必要があります。検索段階で必要な根拠を取りこぼしていると、生成側でどれだけ工夫しても回答は改善されないからです。
回答がずれている場合、まず「上位に返ってきた根拠ドキュメントは期待どおりか」を確認します。根拠が正しいのに回答がおかしければ生成側の調整、根拠自体がずれていれば検索側(チャンク分割・メタデータ・同義語対応など)の改善が優先です。
この切り分けをせずに「プロンプトを直す」「モデルを変える」といった対処に走ると、工数だけかかって効果が出にくい状況に陥りがちです。
簡易評価テンプレート(20問×上位3根拠)の構成と使い方
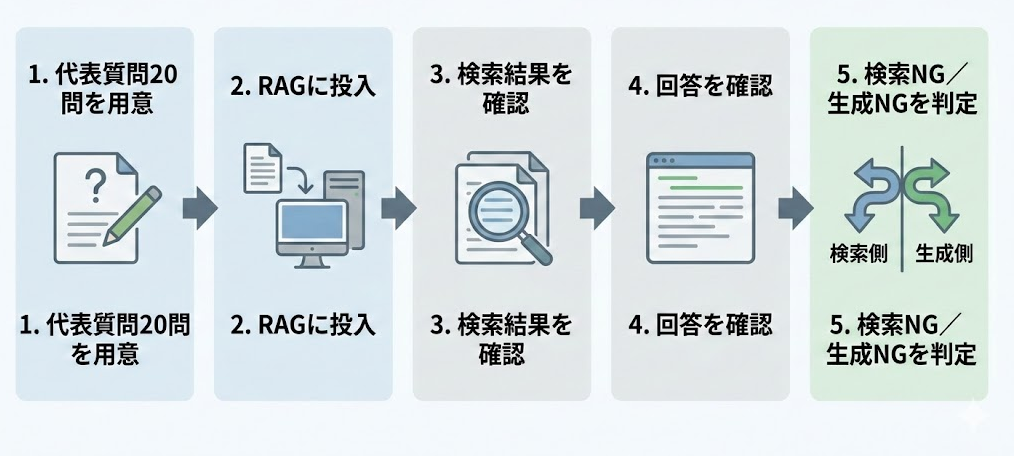
「検索と生成のどちらがボトルネックか」を手早く判定するには、次の4列で構成する簡易評価テンプレートが役立ちます。
- 質問(20問) — 代表質問セットから選んだ質問
- 期待回答の要旨 — 正解とみなす回答の骨子を2〜3行で記載
- 上位3根拠 — システムが返した根拠ドキュメントのタイトルまたは要約
- 判定欄 — 検索OK / 検索NG、生成OK / 生成NGの2軸で記録
各質問に対して、まず上位3根拠が期待する情報源と一致しているかを確認します。根拠が的外れなら「検索NG」、根拠は合っているのに回答が不正確なら「生成NG」と記録し��ます。20問を一巡すると、検索NGと生成NGの比率から優先すべき改善領域が見えてきます。
このテンプレートはあくまでスポット評価の道具であり、網羅的な品質保証を代替するものではありません。他のテンプレート群と組み合わせて、改善サイクルの起点として使います。
危険領域の安全設計——答えない設計と根拠提示の考え方
検索・回答の品質を改善しても、社内AIチャットが扱う質問のなかには「回答してはいけない領域」が残ります。個人情報、法務判断、医療相談など、ハルシネーション対策だけでは防ぎきれないリスクを持つ質問群です。ここでは「答えない設計」と「答えるなら根拠を添える設計」の組み合わせ方を整理します。
「答えない設計」と注意喚起の組み合わせ方
危険領域の質問に対する安全設計は、3つの層で考えると整理しやすくなります。
- 回答を控える — 個人情報の照会や法務・医療の最終判断など、AIが答えるべきでないカテゴリをあらかじめ定義します。該当する質問には「この質問にはお答えできません。○○部門にお問い合わせください」と代替の問い合わせ先を返す形が一般的です。
- 注意喚起を添える — 回答はするものの「AIが生成した仮の回答で最終確認が必要」と注記します。社内規程の要約や手続きの概要など、参考情報として返せる範囲に向いています。
- 根拠を提示する — 回答の根拠となったドキュメント名やページを併記します。「どの文書に基づく回答か」が見えると、利用者が自分で裏取りでき、信頼感につながります。
3つの層をどこで切るかは組織のリスク許容度によって変わるため、法務やセキュリティの担当者と合意を取っておくと良いでしょう。悪意のある入力によって意図しない情報が引き出されるリスクもあり、プロンプトインジェクションで機密情報を窃取されるケースも報告されているため、回答制御のルールは技術面だけでなく運用面でも定期的な見直しが望ましいです。
危険質問10問テンプレートの考え方と匿名化の原則
「危険な質問」を洗い出すテンプレートを社内で作るとき、テンプレート自体が機密や個人情報を含んでしまうと本末転倒です。安全に作るための考え方を3点にまとめておきます。
- 匿名化・一般化する — 質問例に実在の氏名・部署名・案件名を入れません。「○○さんの給与は?」ではなく「特定社員の給与情報を聞かれた場合」のように、一般化した型で記述します。
- カ�テゴリで分類する — 個人情報、法務判断、医療・健康、機密プロジェクト、人事評価などのカテゴリごとに2〜3問ずつ用意すると、網羅性が上がります。10問は目安なので、組織の規模や業務領域に合わせて調整して構いません。
- 権限を絞る — 危険質問のリスト自体が「AIの弱点一覧」になり得るため、テンプレートの閲覧・編集権限は管理者と運用担当に限定しておくと安心です。
危険質問テンプレートは導入直後の初期設定だけでなく、運用中に新たな危険パターンが見つかったときの追加・更新にも使えます。最初から完璧を目指すより、まず10問で始めて四半期ごとに見直すくらいの運用が現実的でしょう。
3か月で整える改善の進め方と運用体制
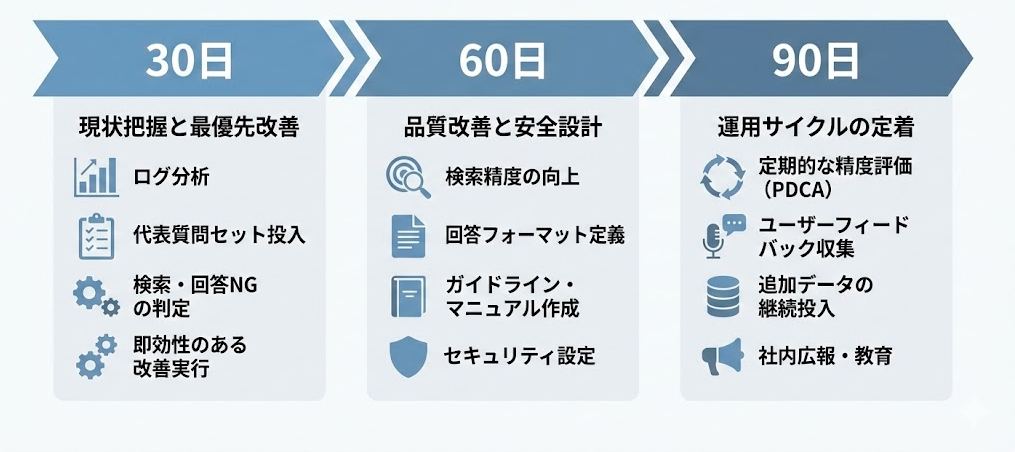
原因の切り分けと安全設計の整理が進んだら、残るのは「いつ・何から手をつけるか」の判断です。改善テーマは多岐にわたるため、すべてを同時に進めるのは現実的ではありません。ここでは、3段階に分けた優先度の考え方と、運用を続けやすくするための体制例を整理します。
最初の1か月——現状を見て、直す場所を1つ決める
最初の1か月で取り組みたいのは「いま何が起きているかの把握」と「即効性のある改善1つへの着手」です。
- RAG適否の確認: FAQ・検索・ワークフロー整備で足りる�業務を除外し、RAGで解くべき質問に絞る
- 現状把握: 代表質問20問のスポット評価がまだであれば、ここで実施し、7パターンのどこにボトルネックがあるかを切り分ける
- 測定開始: 代表質問ごとに、AI回答を得て確認するまでの時間と、既存手段で解決する時間を比べる
- 改善着手: 対応コストが低く効果が見えやすいものを1つ選んで着手する
最初の1か月で全パターンを解消しようとすると手が回らなくなりがちです。診断と1テーマに絞ると、2か月目の判断材料も揃います。
2か月目——検索・回答品質と安全設計を整える
2か月目までに扱いたいのは「検索・回答の品質改善」と「危険領域の安全設計を形にする」ことです。
- 品質改善: 簡易評価テンプレート(20問×上位3根拠)で定点観測し、検索・生成のどちらにボトルネックがあるかを継続的に把握する
- 安全設計: 危険質問10問テンプレートをもとに「答えない設計」の実装を進める
両方を同時に走らせると判断が混乱しやすいため、週単位で交互にレビューする形が進めやすいでしょう。品質改善の効果は利用者に見えにくいことがあるため、「この質問の回答が変わった」という具体例を社内共有すると改善が伝わりやすくなります。
3か月目——改善が続く運用にする
3か月目の目標は「改善を1回で終わらせず、繰り返し回せる仕組みを作る」ことです。
- フィードバック導線: 利用者が「役に立った / 立たなかった」を返せる仕組みを整備する
- 評価サイクル: 月次で定点評価を行い、改善の優先度を見直す
導線や用途定義の課題はフィードバックなしには見つけにくいものです。継続のためには担当者を明確にし、週次・月次でKPI進捗を確認するサイクルが前提となります。
運用を続けやすい体制の考え方
RAG定着のために「どんな体制要素を揃えればよいか」を整理します。
体制はプロジェクトオーナー・運用管理者・コンテンツ担当・技術担当に分けておくと、対応先が明確になります。兼任でも構いませんが、「誰が見ているか」がチーム内で共有されていることが重要です。
評価指標としては、定量面(利用者数・月間質問件数・回答精度)と定性面(ユーザー満足度)に加えて、冒頭で挙げた「到達時間の逆転」を定期的に確認します。AI回答を得て確認するまでの時間が、既存手段で解決する時間を下回っているかを週次・月次で見ると、改善の優先度を見直しやすくなります。
担当者と定例サイクルが揃うことで、導入して終わりという状況を防ぎやすくなります。
最後に
社内AIチャットが使われない原因は、モデル性能だけではなく知識・信頼・導線・運用の4系統に収束しがちです。ログ基盤がなくても、まずはRAGで解くべき業務かを確認し、代表質問20問のスポット評価でボトルネックの当たりをつけるのがおすすめです。
ただし�、セルフ診断だけでは見えにくい領域もあります。
複合要因が絡むケースや、技術課題に見えて実は承認・権限・ガバナンスの問題だったケースは、自社だけでは気づきにくいものです。「判断に迷う」「優先順位が決まらない」という状況であれば、お問い合わせからご相談ください。
よくある質問
- ログがない状態でも社内AIチャットの課題を特定できますか?
- 代表質問20問と危険質問10問を用意し、回答の正確さ・根拠の有無・安全性をスポット評価することで、ログがなくても主要なボトルネックを推定できます。
- 代表質問セットは何問くらい用意すれば十分ですか?
- 目安は代表質問20問+危険質問10問です。組織の規模や業務範囲に応じて調整するのがおすすめです。
- RAGの検索精度と回答精度はどう区別して評価すればよいですか?
- 検索精度は「正しい文書が上位に出ているか」、回答精度は「取得した文書をもとに正確な回答を生成しているか」で分けて確認します。根拠の存在チェックと回答内容の照合を別ステップで行うと切り分けやすくなります。
- 危険質問テンプレートを社内で作るとき機密情報が漏れませんか?
- テンプレートは匿名化・一般化した質問の型として作成し、実際の機密情報や個人情報は含めない設計にします。権限設定やアクセス制御もあわせて確認すると良いでしょう。
- 改善の優先順位はどう決めればよいですか?
- 最初の1か月で症状の切り分けと検索品質の確認、2か月目で回答品質と安全設計の改善、3か月目で運用体制とフィードバック導線の整備を進める��と、手戻りを減らしやすくなります。
- RAGではなくFAQや検索で十分なケースはありますか?
- あります。単純な定型FAQ、文書名が分かっている検索、最終的に担当者承認が必須の業務は、RAGよりもFAQ・検索・ワークフロー整備の方が定着しやすい場合があります。
- 運用担当者がいない場合でも改善サイクルは回せますか?
- 兼任でも、月次の見直し・フィードバック収集・評価観点の3つを決めておけば改善サイクルは回せます。ただし、責任の所在があいまいなまま進めると形骸化しやすい点には注意が必要です。
更新履歴(最終更新: 2026年5月10日)
- RAGの適否判断と改善手順を更新
- 初回公開
著者プロフィール
大崎 一徳 / エンジニア
中小企業向けに、AI導入・業務自動化・ツール開発を支援しています。 PoC から本番運用まで一貫して伴走し、「現場で使われ続ける仕組み」をつくることを大切にしています。
Udacity Deep Learning Nanodegree 修了
日本ディープラーニング協会(JDLA)主催 第1回ハッカソン GPU Eater賞受賞(チーム ニューラルポケット)
関連ガイド

AIエージェントに業務ツールをどこまで任せるか
AIエージェントに会計・メール・決済などの業務ツールをどこまで任せるか。権限、人間確認、監査ログの線引きを実務目線で整理します。

AIエージェントが増えると壊れやすい理由:分業・承認・記憶で組織化する
AIエージェントを複数使い始めると、受け渡し、重複、確認漏れ、責任境界の問題が起きやすくなります。何体使うかではなく、分業・承認・記憶をどう設計するか、どの操作に人間の確認を残すかという視点で組織化を解説します。

本番ログからLLM回帰テスト用データセットを作る最小構成|収集からCI接続まで
LLM/エージェントの本番ログから失敗ケースを自動抽出し、回帰テスト用の評価データセットへ変換してCIゲートに接続する最小構成を、収集・抽出・正規化・ラベリング・データセット化・CI接続の6ステップで解説します。


