
OpenClawをSlackにつなぐ前に決めること:誰の権限で動かすのか
個人でOpenClawを触っていると、「これ、Slackにつないだら社内でも使えるのでは」と考えるかもしれません。
たとえば、情シスの数人だけでSlack botを作り、社内ナレッジ確認やファイル操作を少しずつ任せてみると、最初は便利です。
でも、そのGatewayが誰の権限で動いているのか、誰がbotに話しかけられるのか、どのツールまで実行できるのかが曖昧なままだと、Slackの入口はそのまま社内データやツール権限への入口になります。
OpenClawを社内Slackやチャットから使えるようにする前に、まず決めるべきなのは「このGatewayは誰の権限で動くのか」です。共有してよい利用者、Gatewayへ到達できる範囲、許可するツールを狭く説明できるなら、小さく試せます。そこが曖昧なら、設定を増やす前に境界を分ける方が安全です。
先に大まかな判断だけ置くと、次のように分けられます。
| 状態 | 判断 |
|---|---|
同じ権限の少人数・read中心・loopback / tailnet内 | 小さく試す |
| 部署横断・writeあり・proxy検討中 | まだ設計する |
| 顧客・委託先混在・無認証公開・強いツール権限 | 避ける |
この記事で決めることは、共有する人、到達できる範囲、許可するツール、守るデータの4つです。
Slackにつなぐと、何が変わるのか
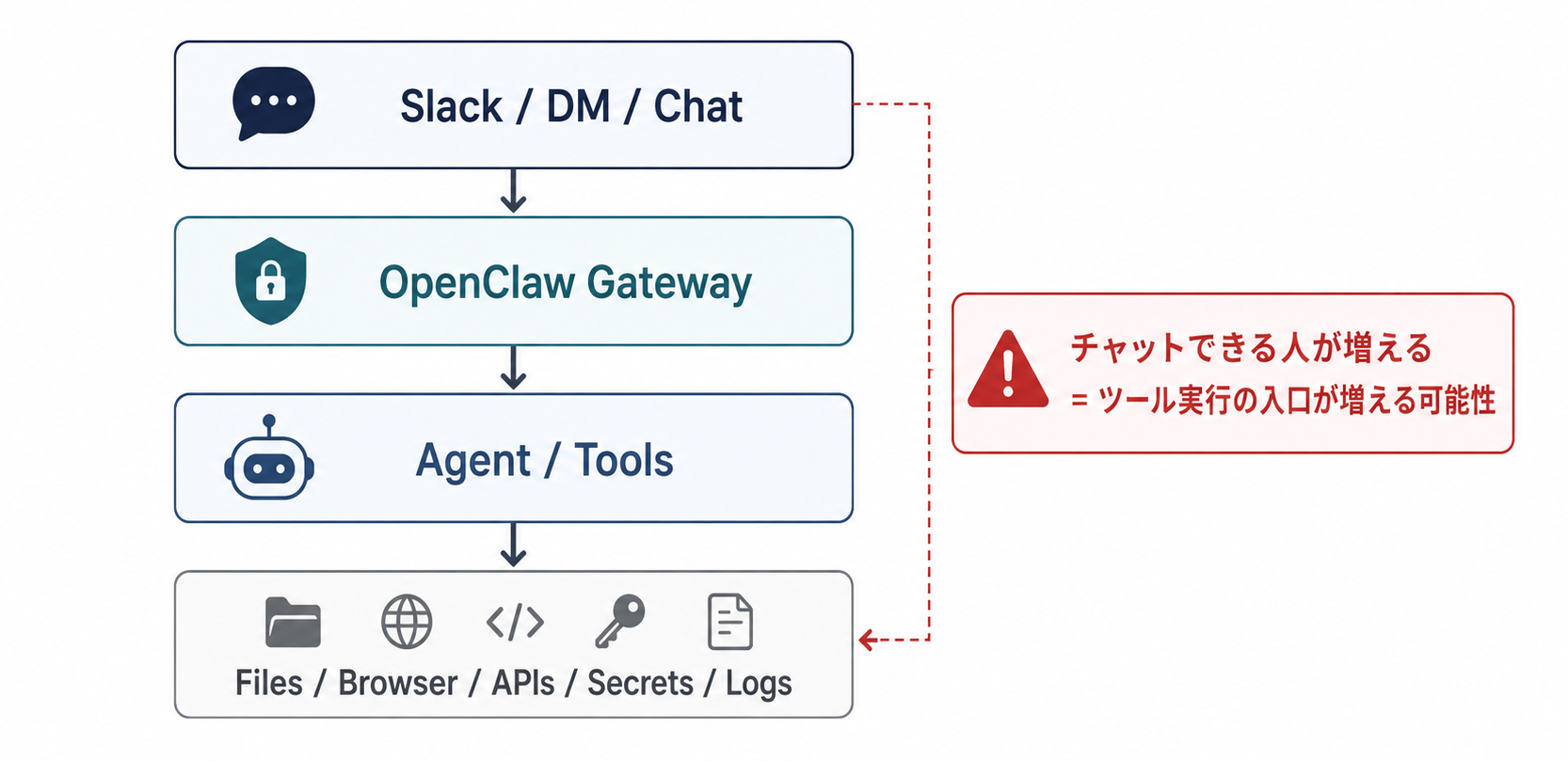
SlackからAIエージェントを呼べるようになると、便利なので複数人に開放したくなります。しかしGatewayは単なる中継ではなく、エージェントやツール実行に近い制御面です。チャットできる人が増えると、ツール実行を始められる入口も広がります。
AIエージェントを社内に入れる時、「どのツールを許可するか」から考えることが多いと思います。でも実際には、その前に「誰の代理人として動くのか」を決めないと、あとから設定で帳尻を合わせることになります。最初に壊れやすいのは、ツール設定そのものよりも、チャットの入口、Gatewayの権限、社内データの境界が�曖昧になることです。
この記事では、OpenClawの社内導入を検討する中小企業の技術責任者、情シス、運用担当者向けに、共有してよい利用者、Gatewayへ接続できる範囲、最初に許可する業務の3点を、導入前メモとして書き出せる形にします。細かな設定手順ではなく、「何を決めてから進めるか」に絞ります。
これは、OpenClawが危ないという話ではありません。個人で便利に使う前提と、社内で複数人が使う前提では、先に決めるべき境界が変わるという話です。
OpenClaw公式のSecurityページは、OpenClawを「personal assistant trust model」として説明しています。1つのGatewayは、1つの信頼された運用者の境界として見る設計です。OpenClawは、敵対的な複数利用者を1つの環境で隔離するための境界ではない、という趣旨も同じ資料で示されています。
そのGatewayは誰の権限で動いているのか
最初に決めたいのは、1つのGatewayを誰と共有してよいかです。
Gatewayは単なる中継ではなく制御面として見る
OpenClawのGitHub READMEでは、OpenClawは自分のデバイスで動かすパーソナルAIアシスタントであり、Gatewayはチャットチャネルとエージェント、ツールをつなぐcontrol planeとして説明されています。ここで大事なのは、Gatewayが単なる中継サーバーではなく、ツール実行や設定、資格情報に近い場所を扱う制御面になることです。
会話を分けて見せる仕組みは、利用者ごとの権限分離の代わりにはなりません。同じSecurityページでも、sessionKeyやsession ID、labelはルーティングのための選択子であり、認可トークンではないと説明されています。
共有してよい人と分けたい人を書き出す
社内で最初に書き出すなら、まずは次の3つから始めると整理しやすくなります。
- 同じGatewayを共有してよい人
- 別Gateway、別OSユーザー、別ホストに分けたい人
- Gateway上で触れる業務データと、触れさせない業務データ
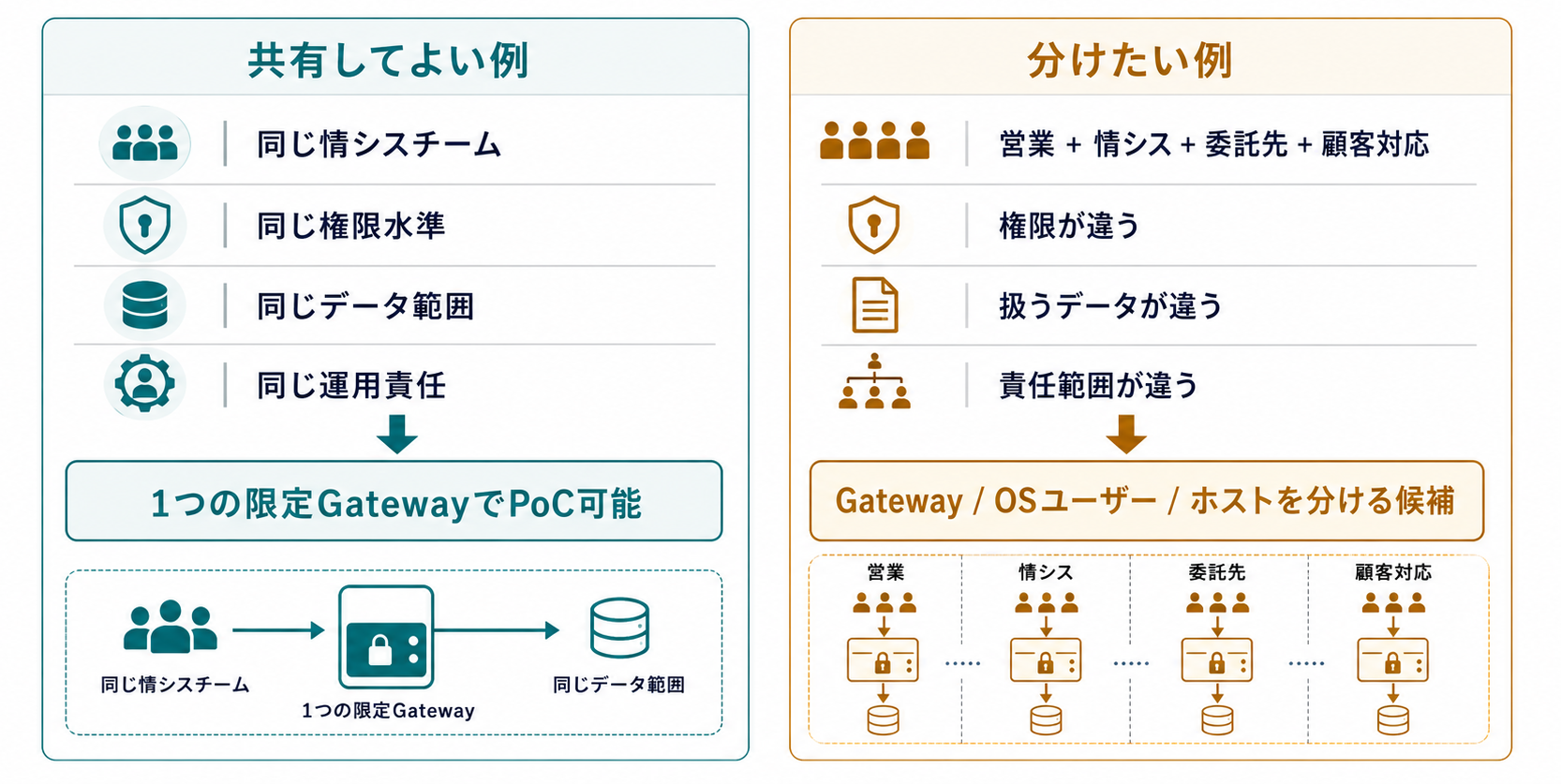
たとえば、同じ情シスチーム内で限定的に使うPoCと、営業・外部委託先・顧客対応窓口まで含める運用では、同じ設計にはできません。
想定例として、同じGatewayを4名の情シス担当で共有し、ファイル操作ツールも許可しているケースを考えます。この場合、チャット上の会話が分かれて見えていても、それは利用者ごとの権限分離とは限りません。誰かが許可したツール権限や、Gatewayが到達できるファイル範囲を、他の利用者の指示からも使えてしまう構成になっていないかを確認する必要があります。
そのため、同じチー�ム、同じ権限水準、同じデータ範囲、同じ運用責任で説明できるなら、1つの限定Gatewayから試せる余地があります。部署ごとに扱うデータが違う、委託先や顧客向けの利用者が入る、同じ資格情報を共有させたくない、といった条件があるなら、GatewayやOSユーザー、可能ならホストを分けるところから考える方が自然です。
誰がGatewayに到達できるのか
個人的には、社内利用で一番怖いのは「少し便利にするために、到達できる範囲を広げすぎること」だと思っています。次に見るのは、Gatewayへどこから接続できるようにするかです。
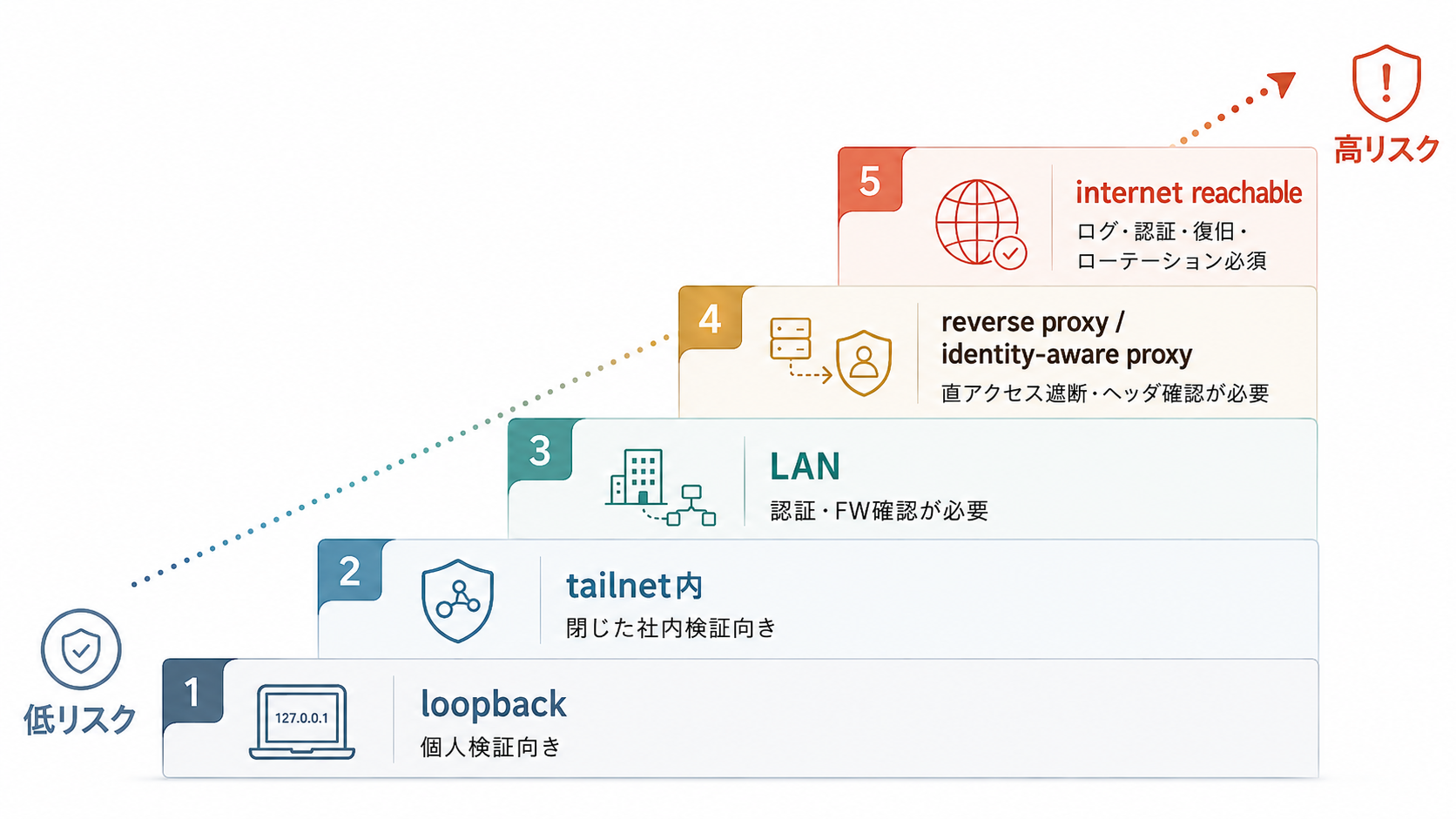
まずは閉じた範囲から考える
限定導入では、Gatewayへ接続できる範囲をできるだけ狭く置くところから考えます。OpenClaw公式のSecurityページでは、Gatewayのbind modeとして、既定のloopbackはローカルのみ接続可能と説明されています。一方で、非loopback bindは攻撃面を増やすため、共有トークンやパスワード認証、厳格なファイアウォールを前提に限定利用する考え方が示されています。無認証で0.0.0.0へ公開する構成は、避けるべき候補として扱うのが妥当です。
Tailscaleを使う場合も、tailnet内に閉じる使い方と、Funnelでインターネットから到達できるようにする使い方は分けて考える必要があります�。OpenClaw公式のTailscaleページでは、Tailscale Serveはtailnet内、Funnelはpublic HTTPSとして説明され、どちらもGatewayをloopbackにbindしたまま使う構成が示されています。Tailscale Funnelの公式ドキュメントでも、Funnelは特定ポートをインターネット上で利用可能にする機能として扱われています。
そのため、Funnelは即NGではありません。ただし、Funnelを使うなら、Gatewayはloopback bindのままにし、Gateway認証、Funnel利用権限、ログ、token/passwordのローテーション、停止手順まで確認します。そこまで説明できない段階では、tailnet内利用やSSH tunnelに閉じる方が判断しやすくなります。
外へ広げるほど確認事項が増える
公開先は、次の順に運用条件が重くなると考えると分けやすくなります。
- ローカルだけで使う
- 自分または社内の閉じたネットワークから使う
- LAN内で使う
- リバースプロキシやidentity-aware proxyの後ろで使う
- インターネットから到達できる形にする
小さく試す段階では、loopbackまたはtailnet内に閉じる候補から始めます。LAN、リバースプロキシ、インターネット公開へ広げるほど、業務上の必要性だけでなく、認証、直アクセス遮断、ログ、token/passwordのローテーション、復旧手順まで説明する項目が増えます。外部公開は、この一式を社内で説明できるまで待つ、と決めておく方が進めやすくなります。
同じSecurityページでは、token、password、trusted-proxy認�証の考え方や、token/passwordのローテーション手順も扱われています。ただし、Gateway HTTP bearer authは実質的にoperator accessとして扱うべき境界である、という注意もあります。部分的な権限のつもりで配るものではなく、誰に渡すか、どこに保管するか、漏れた時にどう止めるかまでセットで考える対象です。
誰がbotに話しかけられるのか
OpenClawをチャットから使う場合、「誰がbotにメッセージを送れるか」は、そのままツール実行を始められる人の範囲になります。
DMとグループで入口を分ける
OpenClaw公式のPairingページでは、未知のDM送信者には短いコードが発行され、承認されるまでメッセージは処理されない仕組みが説明されています。Securityページでも、DM policyとしてpairing、allowlist、open、disabledが扱われ、openは明示的なopt-inを前提にする位置づけです。
グループやチャンネルで使う場合は、groupPolicyやgroupAllowFromで、誰の発言を受けるかを設計できます。ここでも大事なのは、チャネルの許可とGateway内の権限分離を混同しないことです。allowlistやpairingは「話しかけられる人」を制御する入口です。相互に信頼できない人を、同じGateway上で安全に分離する仕組みとして過信しない方がよいでしょう。
会話の分離と権限分離を混同しない
複数人がDMできるshared inboxのような運用は便利です。Securityページでは、shared inbox的な運用ではsession.dmScope: "per-channel-peer"などで会話コンテキストを分ける考え方が示されています。同時に、共有DMと広いツール権限を同居させない注意もあります。
同じ情シスチーム内など、同じ権限セットを共有してよい相手に限るなら、dmScopeで会話の混線を減らし、許可ツールを狭くした限定運用から始める、という整理はできます。避けたいのは、shared inboxそのものではなく、誰が何を実行できるかを決めないまま権限を広げることです。
社内説明では、まず「DMで使う人」と「グループで使う人」を分けて表にすると、議論が進みます。そこに、許可するツールと触れるデータを並べると、どこから限定導入できるかが見えやすくなります。
小さく試すなら、どこまでに絞るか
OpenClawに限らず、AIエージェント導入で失敗しやすいのは、最初から「全社で便利に使えるもの」を目指すことだと思っています。まず1つの業務、1つのチャネル、1つの権限セットに絞ります。
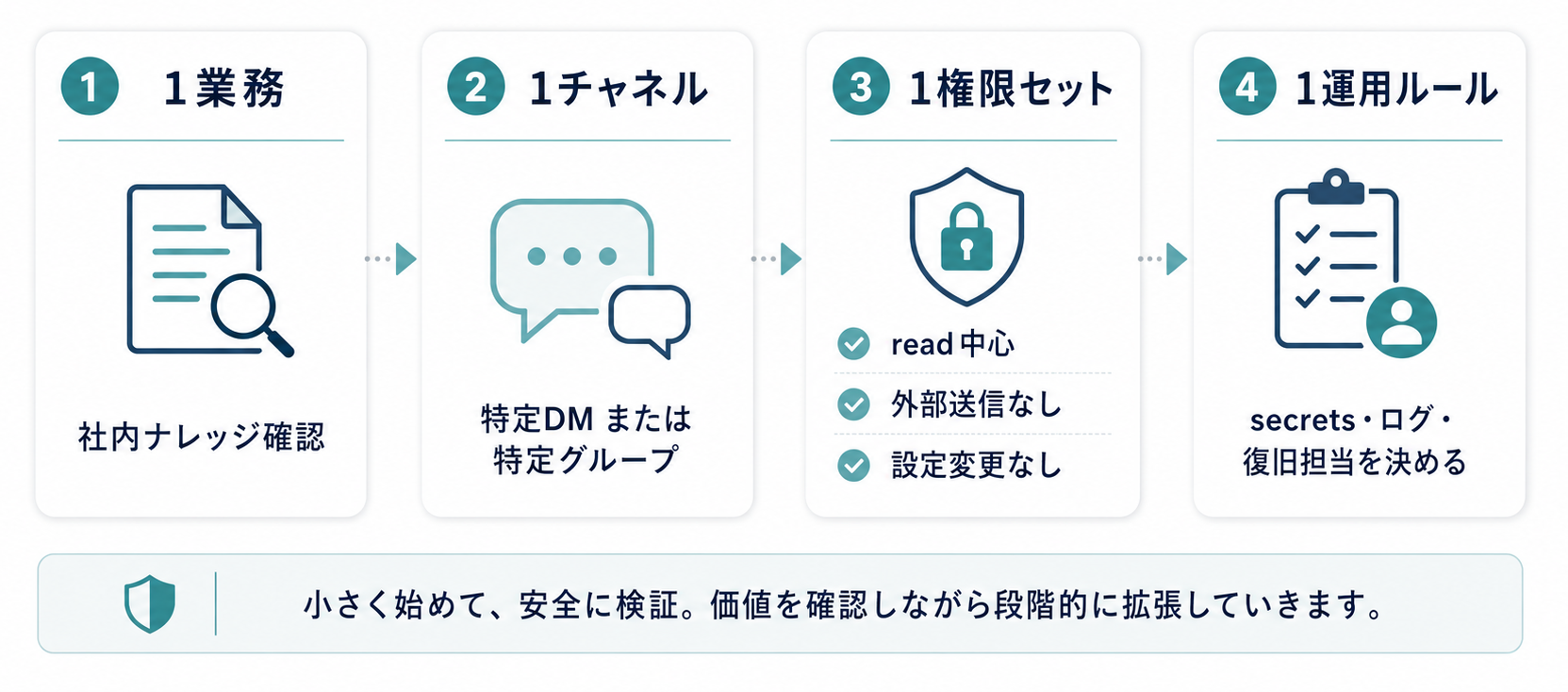
まず1業務・1チャネル・1権限セットに絞る
たとえば、次のように決めます。
- 対象業務: 社内ナレッジの確認、定型作業の補助など
- 使うチャネル: 特�定のDMまたは特定グループだけ
- 触れるデータ: 個人情報、顧客秘密、管理者権限を含まない範囲
- 許可するツール: 業務に必要なものだけ
- 禁止するツール: 設定変更、スケジュール登録、外部送信、永続化につながるもの
最初のルールは、特定グループから社内ナレッジ確認だけを許可し、外部送信、設定変更、永続化につながるツールはdenyにする、という粒度まで狭めると判断しやすくなります。これなら、試す業務、指示できる人、触れるデータ、止める権限を1枚で説明できます。
OpenClaw公式のTools and Pluginsページでは、tools.allowとtools.denyでツール権限を制御でき、両方に記載がある場合はdenyが優先されると説明されています。Securityページでは、gatewayやcronなど、設定変更やスケジュール登録に関わるツールを、未信頼コンテンツを扱う面では既定拒否にする考え方も示されています。
状態保存領域と資格情報も導入条件に入れる
もう1つ、PoCの時点で後回しにしない方がよいのが、状態保存領域と資格情報です。Securityページでは、~/.openclaw/または$OPENCLAW_STATE_DIR配下に、config、チャネルcredentials、auth-profiles、APIキーやOAuth token、セッショントランスクリプト、プラグイン、サンドボックス作業領域などが保存され得ると説明されています。
これは、守る場所が明確になるという利点でもあります。一方で、そこに重要な情報が集まりやすいということでもあります。ディレクトリやファイル権限、ログの残し方、資格情報のローテーション、再構築手順は、正式導入後ではなく、限定導入の条件に入れておくと安心です。
MicrosoftのAzure Pipelinesセキュリティガイダンスでも、self-hosted agentは可能な限り低権限の専用アカウントで実行することが推奨されています。OpenClaw固有の仕様ではありませんが、社内でツール実行を任せる仕組みを扱うときの考え方として参考になります。
進める・待つ・避けるの判断表
導入前の判断は、進める・待つ・避けるの3つに分けておくと扱いやすくなります。ここでの目的は、完璧な設計を一度で作ることではありません。自社で小さく試せる範囲と、まだ広げない範囲を分けることです。
まず全体像だけを見るなら、次のように分けると判断しやすくなります。
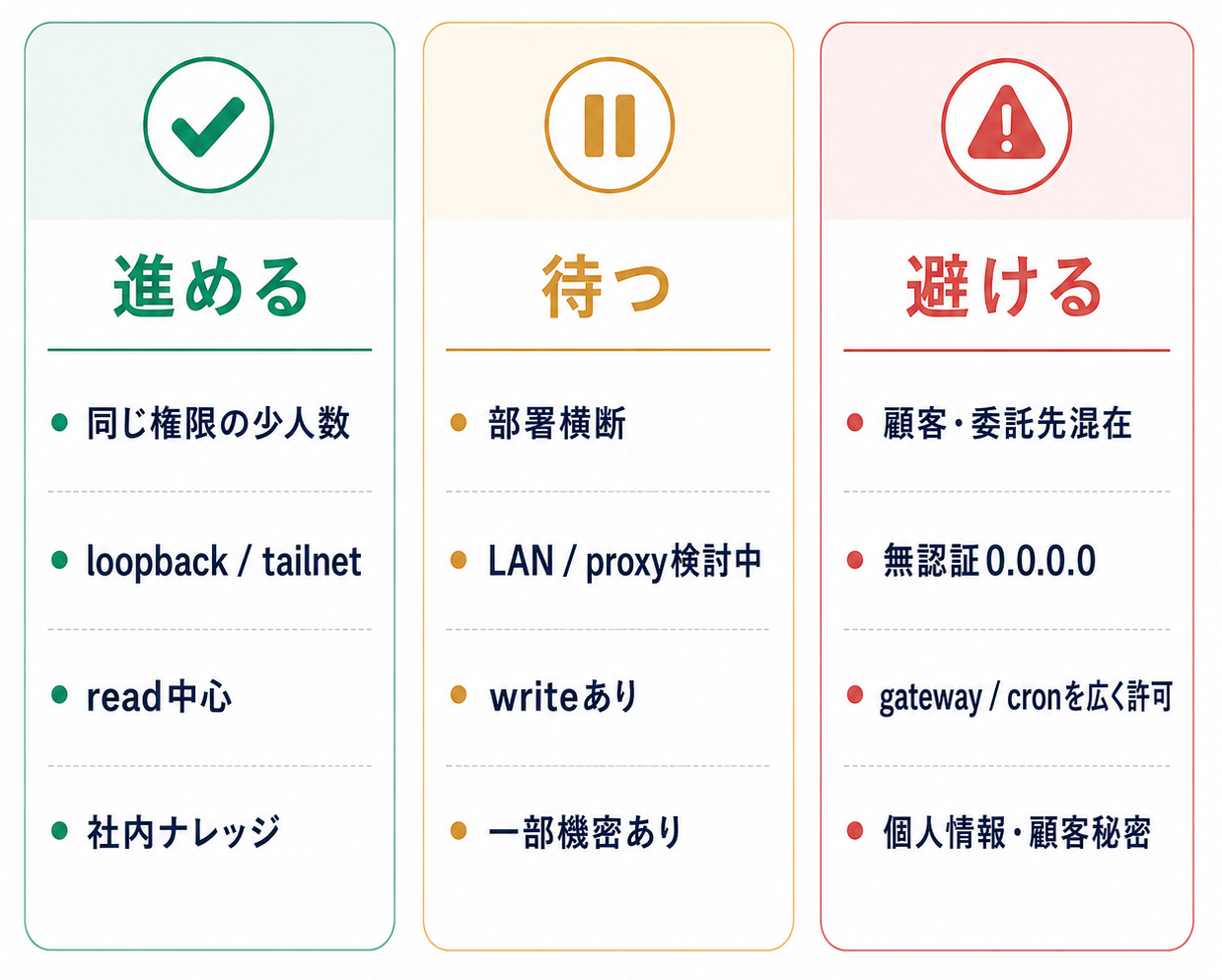
| 観点 | 進める | 待つ | 避ける |
|---|---|---|---|
| 利用者 | 同じ権限の少人数 | 部署横断 | 顧客・委託先混在 |
| 公開範囲 | loopback / tailnet | LAN / proxy検討中 | 無認証0.0.0.0 |
| ツール | read中心 | writeあり | gateway / cronを広く許可 |
| データ | 社内ナレッジ | 一部機��密あり | 個人情報・顧客秘密 |
限定導入に進めやすい状態
次がそろっていれば、まず1つの業務で試す判断に進みやすくなります。
- 1つのGatewayを共有してよい人が明文化されている
- Gatewayへ接続できる範囲が最小化されている
- DM、グループ、allowlist、pairingの扱いが決まっている
tools.allowとtools.denyで、許可する実行範囲を絞っている~/.openclaw/やOPENCLAW_STATE_DIRを重要資産として扱っている- token、password、secrets、ログ、再構築手順の担当が決まっている
- 導入対象版の設定内容、Securityページ、リリースノート、
openclaw doctor、必要に応じてopenclaw security audit --deepの結果を確認している
もう少し整理してから進めたい状態
次の論点が未整理なら、社内展開や外部公開は待つ方がよいです。
- shared inboxと広いツール権限を同時に使いたい
- Gatewayをインターネットから到達可能にしたい
- trusted-proxy認証を使うが、直アクセス遮断やヘッダの扱いが決まっていない
- 個人アカウントやログイン済みブラウザを業務自動化に使いたい
- どのデータがログやトランスクリプトに残るか説明できない
ログイン済みブラウザが必要な業務でも、最初は業務専用アカウント、専用ブラウザプロファイル、専用VMなどに分けられるかを先に確認すると、個人利用と業務利用の境目を説明しやす��くなります。
避けたい構成
少なくとも初期導入では、次の構成は避ける対象として扱うのが現実的です。
- 無認証で
0.0.0.0へ公開する sessionKeyやdmScopeを権限分離として扱う- 相互に信頼できない利用者を同じGatewayに乗せる
- DMをopenにしたまま、強いツール権限を許可する
- Gateway tokenを部分権限のように配布する
- secretsやログの保管場所を決めずに本番業務へ進める
MITREのATLAS OpenClaw Investigationでは、公開されたOpenClawのcontrol interface、資格情報アクセス、prompt injection、悪性skillによる供給網リスクなどが調査例として扱われています。ここから言えるのは、OpenClawが一律に使えないということではありません。公開面、ツール権限、資格情報、復旧手順を分けて設計しないと、便利な利用経路が強い権限の利用経路にもなり得るということです。
限定導入では、skillsやpluginsは業務に必要なものだけを明示的に信頼し、追加、更新、無効化の担当を決めてから広げる、くらいの小さな運用ルールから始めます。
自社でどこから始めるか迷う場合は
個人的な意見としては、OpenClawを社内利用で考えるときに、最初から全社共通アシスタントを目指す必要はありません。むしろ最初に見るべきなのは、このGatewayを、誰の代理人としてなら説明できるか、です。
OpenClawを社内で使うかどうかは、「リ�スクをゼロにできるか」ではなく、「自社の業務で、信頼する人、到達できる場所、許可するツール、守る情報を狭く定義できるか」で判断すると進めやすくなります。同じ役割、同じ責任、同じデータ範囲で説明できる少人数から始め、外部公開、部署横断、強いツール権限は後から1つずつ増やす。この順番の方が、便利さと安全性の両方を保ちやすくなります。
まずは、自社の状況を次の3点で確認してみてください。
- 同じGatewayを共有する人を、名前や役割で説明できるか
- Gatewayの公開先と、外部公開を待つ条件を説明できるか
- 許可するツール、触れるデータ、secrets・ログ・復旧手順の担当を説明できるか
この3点を書き出すと、1つの業務、1つのGateway、1つのチャネルから始められる範囲と、まだ広げない方がよい範囲が見えやすくなります。
ここで迷う場合は、ツール設定だけを詰めるよりも、社内で説明できる運用境界を先に整理すると判断しやすくなります。
PASHでは、共有したい利用者、公開したい範囲、許可したいツール、secrets・ログ・復旧手順の現状をもとに、社内利用に進める範囲、分けるべき境界、まだ待つべき構成を一緒に整理できます。
よくある質問
- OpenClawは社内利用に向かないということですか?
- そうではありません。この記事で見ているのは、OpenClawを社内で使う前に、個人利用と同じ前提で広げてよい範囲と、先に分けておきたい範囲を整理することです。1つの業務、1つのGateway、信頼できる利用者に絞るなら、小さく試せる余地はあります。
- Tailscaleを使えば外部公開ではないと考えて�よいですか?
- tailnet内に閉じる使い方と、Funnelのようにインターネットから到達できる使い方は分けて考える必要があります。社内説明では、誰が到達できるか、どの認証を通るか、直アクセスを防げているかをセットで確認する方が安全です。
- 1つのGatewayを複数人で使ってもよいですか?
- 同じ権限水準、同じデータ範囲、同じ運用責任で説明できる相手に限るなら、限定的に検討できます。部署、委託先、顧客対応などで扱うデータや責任が変わる場合は、Gateway、OSユーザー、ホストを分ける候補として見た方が自然です。
- 最初に許可する業務はどう選べばよいですか?
- 失敗しても戻しやすく、顧客秘密や管理者権限を直接扱わず、効果を確認しやすい業務から選ぶのが現実的です。たとえば社内ナレッジ確認や定型作業の補助のように、使うチャネル、許可するツール、触れるデータを1枚で説明できる範囲から始めます。
更新履歴(最終更新: 2026年5月10日)
- タイトル、冒頭、見出し、Tailscale/Funnelの説明、公式出典、判断表、FAQ表示の整形を更新
- 社内利用時の信頼境界と導入判断の説明・図版を更新
- 初回公開
著者プロフィール
大崎 一徳 / エンジニア
中小企業向けに、AI導入・業務自動化・ツール開発を支援しています。 PoC から本番運用まで一貫して伴走し、「現場で使われ続ける仕組み」をつくることを大切にしています。
Udacity Deep Learning Nanodegree 修了
日本ディープラーニング協会(JDLA)主催 第1回ハッカソン GPU Eater賞受賞(チーム ニューラルポケット)
関連ガイド

AIエージェントに業務ツールをどこまで任せるか
AIエージェントに会計・メール・決済などの業務ツールをどこまで任せるか。権限、人間確認、監査ログの線引きを実務目線で整理します。

AIエージェントが増えると壊れやすい理由:分業・承認・記憶で組織化する
AIエージェントを複数使い始めると、受け渡し、重複、確認漏れ、責任境界の問題が起きやすくなります。何体使うかではなく、分業・承認・記憶をどう設計するか、どの操作に人間の確認を残すかという視点で組織化を解説します。

本番ログからLLM回帰テスト用データセットを作る最小構成|収集からCI接続まで
LLM/エージェントの本番ログから失敗ケースを自動抽出し、回帰テスト用の評価データセットへ変換してCIゲートに接続する最小構成を、収集・抽出・正規化・ラベリング・データセット化・CI接続の6ステップで解説します。
関連記事

OpenAI Frontierとは?企業でAIエージェントを動かすための「運用の判断軸」
「これ、AIで回せる?」と聞かれた時、どう判断しますか?AIエージェントを単なるチャット相手ではなく「成果物を出す実行者」と定義し、企業で安全に運用するための判断軸を 4要素(共有コンテキスト / 実行 / 評�価・最適化 / 権限・制御範囲) で整理して解説します。

Gitリポジトリは、AIエージェントの「記憶」になるのか
AIとの会話は残っていても、仕事は引き継がれません。resume、AGENTS.md、CLAUDE.md、引き継ぎノートを整理しながら、GitでAIの作業文脈を残す意味を考えます。
