
AIエージェントが増えると壊れやすい理由:分業・承認・記憶で組織化する
複数のAIエージェントを業務で使い始めると、個々の性能とは別に、エージェント間の「受け渡し」や「責任の所在」で問題が起き始めます。1体のAIエージェントなら便利な道具で済みますが、数が増え役割が分かれると問題の性質が変わるのです。
この記事では、その問題がなぜ起きるのか、そして個々のAIの賢さだけでなく組織化(技術的な役割分担や確認の設計)がなぜ重要になるのかを解説します。経営組織論ではなく、あくまで実務上の設計課題の話です。
なお、組織化が必要になるタイミングは「��何体から」と一律に決められるものではありません。実務上は、AIの数よりも、元に戻しにくい操作が入るか、部署や権限の境界を越えるか、受け渡しが何回発生するかで判断する方が現実的です。
AIエージェント1体なら便利。でも、複数になると壊れやすい
AIエージェントを1体だけ使う分には連携の問題は起きにくいのに、なぜ複数を組み合わせた途端に問題が起きるのでしょうか。このセクションでは、問題の性質が個人の能力からチームの連携へとどう変わるかを解説します。
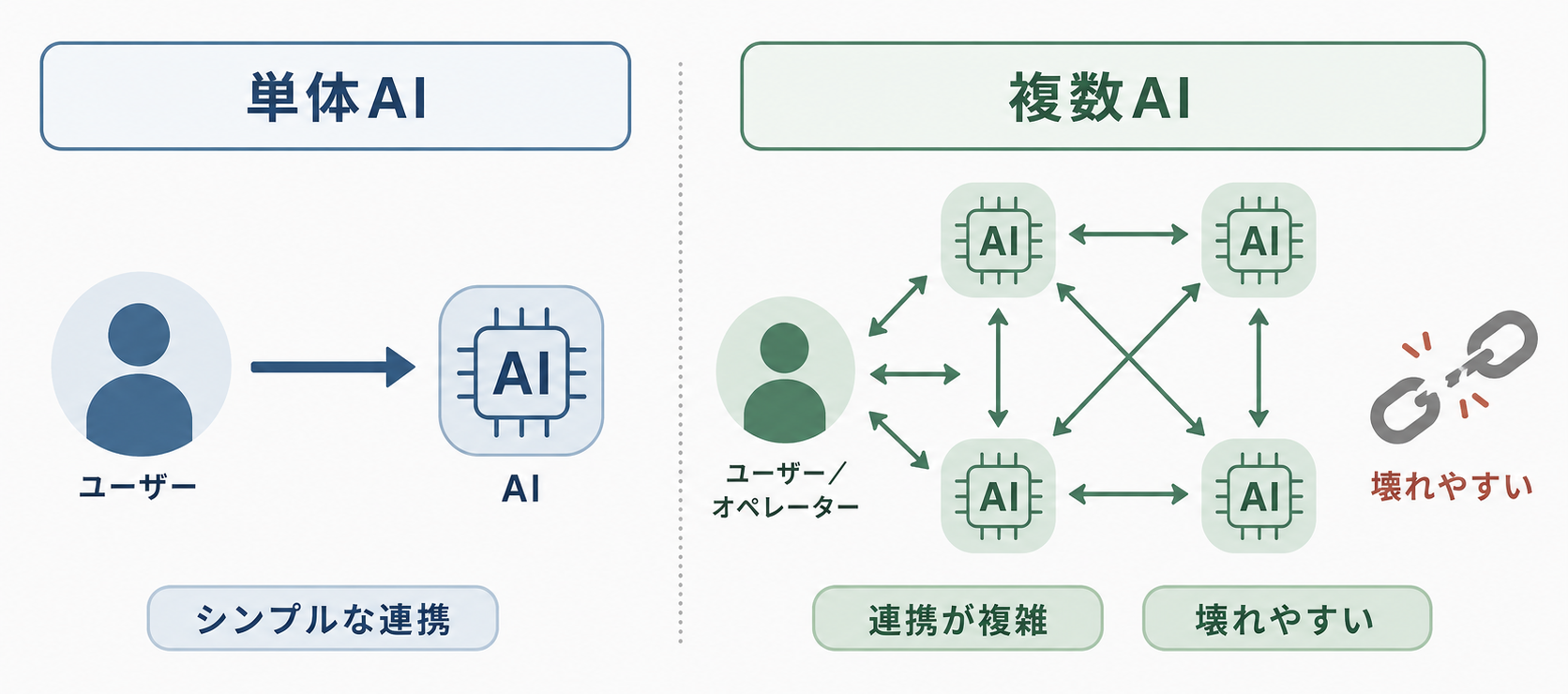
1体だけなら:優秀な「個人」として完結する
単体のAIエージェントは、指示と結果が1対1で対応する世界です。Microsoft Learnでは、単体エージェントはロジックを1体に集約できる構成と説明されています。同資料は、実装と運用の見通しが立てやすい点も示しています。
これは、優秀な「個人」に仕事を依頼する状��況と似ています。期待する役割が明確で、成果物もその個人から直接返ってくるため、やり取りは単純です。ただし、このシンプルさは、エージェントが単独で完結できる範囲のタスクに限られます。
複数になると:仕事の「引き継ぎ」で問題が起きる
エージェントの数が増えると、問題の性質が「個人の能力」から「チームの連携」へとシフトします。そこで新たな課題になるのが、エージェント間の仕事の「引き継ぎ」です。
各エージェントに責務を分担させると拡張性は得られますが、Microsoft Learnでも触れられているように、エージェント間をつなぐ調整、つまりオーケストレーションが必要になります。
もし連携設計が曖昧な場合、個々の出力が優れていても、それらを繋ぐ調整は結局、人間が行うことになります。個々のエージェントが優秀でも、チームとしてはうまく機能しなくなるのです。
この意味で、「まだ数体だから組織化は早い」とは言い切れません。外部送信、本番データの更新、会計や契約の登録など、元に戻しにくい操作が1つでも入るなら、体数が少なくても承認点とログを先に考える必要があります。
なぜ壊れる?AIの連携で起きる5つの問題
複数のAIエージェントを連携させようとすると、なぜかうまくいかない場面が出てきます。問題の多くは、あるAIの出力を次のAIや人間へどう渡すか、いわば「受け渡し」の設計に集まります。こ��こでは、AIが増えた現場で特に起きがちな5つの問題、例えば出力の受け渡しの失敗や作業の重複といった具体的な課題を掘り下げていきます。
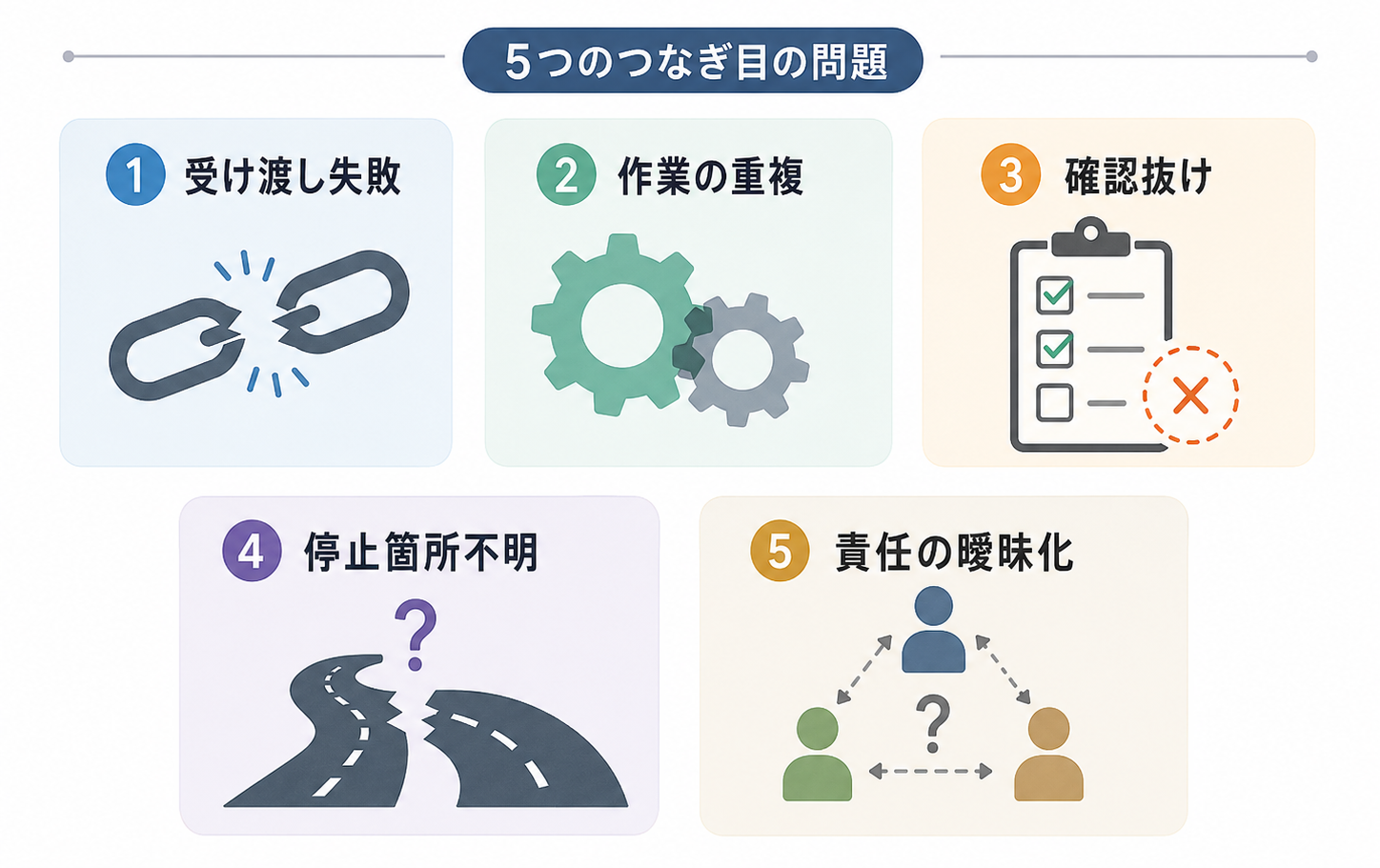
問題1:出力の「受け渡し」がうまくいかない
あるエージェントの出力が、次の入力形式と合わなかったり、情報が不足したりする問題です。これは、各エージェントの役割分担や出力形式を厳密に定義していない場合に起こりがちです。LangChainの解説でも、タスク境界や出力形式の指定不足が問題として挙げられています。
例えば、Slack投稿用の下書きAIと、社内記事用の文章生成AIを別々に使うとします。Slackでは「すぐに試せます」と軽く案内し、記事では「段階的リリース」と慎重に説明する。どちらの出力も単体では自然でも、共通の前提や表現ルールがなければ、最後に人間が整合性を取り直すことになります。
問題2:作業の「重複・矛盾」が起きる
各エージェントの担当範囲が曖昧な場合、同じ調査を何度も繰り返したり、��互いに矛盾する内容を生成したりするケースがあります。
Anthropicの事例でも、曖昧な委譲によってサプライチェーンの近いテーマを複数エージェントが重複調査した例が挙げられています。その結果、人間が調整役を担うことになり、意図しない管理コストが発生しがちです。
問題3:重要な「確認」が抜け落ちる
単体で人間が直接操作するなら、影響の大きな処理の前には誰でも確認を挟みます。難しいのは、複数のエージェントを繋いだ瞬間に、その確認点が構造的に抜け落ちやすくなることです。例えば、調査エージェントが社外情報をまとめ、下書きエージェントがそれを基に顧客向けの文面を作り、送信エージェントが定型連絡として送る、という構成を考えます。
各エージェントは個別には妥当に動いているかもしれません。それでも、調査段階の誤りや古い情報が、途中で誰にも止められないまま顧客への送信まで流れてしまう。各部品が正しくても、連鎖のどこにも人間の確認点が設計されていなければ、本来確認すべき操作が素通りするのです。
ここでも見るべきなのは、AIの体数ではなく操作の戻しにくさです。文章の要約なら後から直せますが、外部送信や本番データの更新は、実行後の取り消しが難しくなります。
問題4:どこで「停止」したか分からなくなる
複数の処理が連鎖すると、どの段階で問題が起きたのか特定が難しくなることがあります。Microsoft Learnでも、各工程のログが不十分だと原因調査に時間を要しがちだと説明されています。マルチエージェントの失敗要因を分析した研究でも、処理が終わる前に途中で止まってしまう「早すぎる終了」や、結果を検証しないまま次に進む「検証の欠如・不足」など、途中停止や確認不足に関わる失敗パターンが整理されています。
問題5:「責任の所在」が曖昧になる
最終的な出力に誤りがあった場合、原因の切り分けが困難になります。AIモデルの限界か、ツールのバグか、あるいは連携設計の不備か、特定しにくくなるためです。結果として、改善サイクルを回しにくくなります。
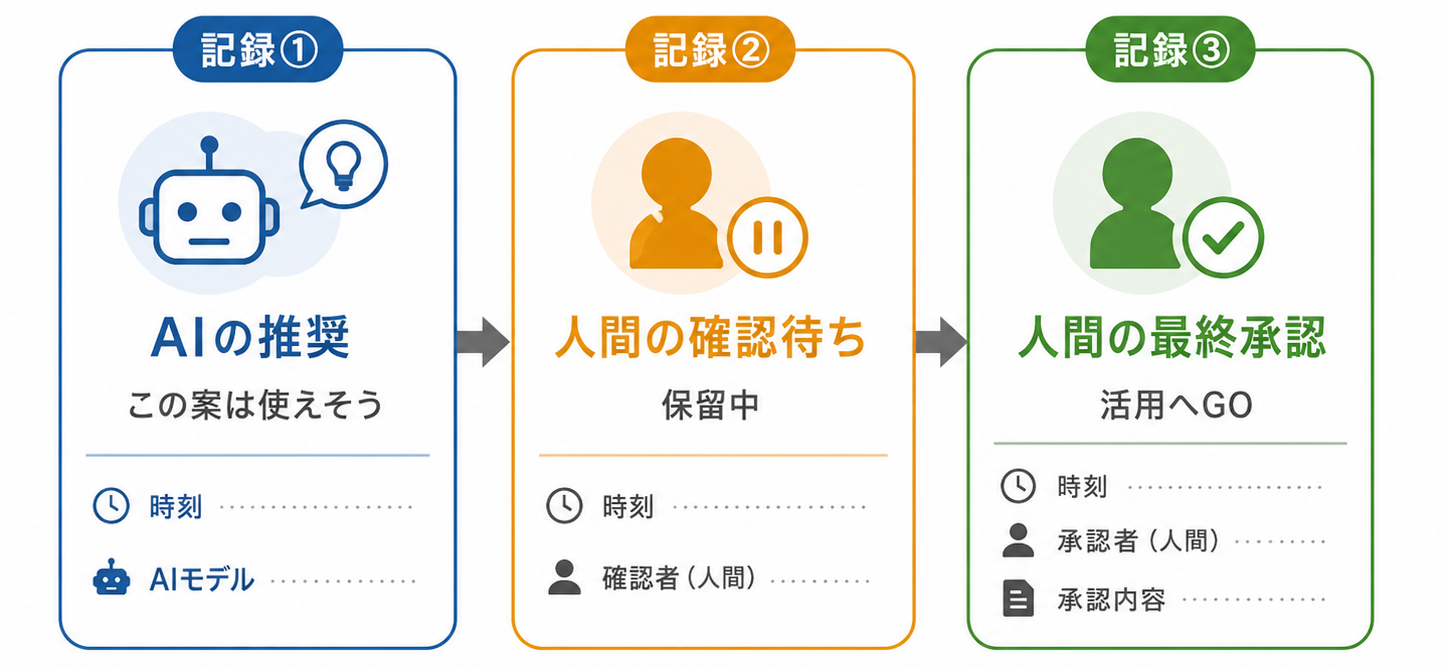
レビュー役をAIに任せる場合も、誰が最終的な承認者なのかを分けておく必要があります。私たちが業務に使っている、Hermes Agent(Nous Researchのエージェントフレームワーク)を使った仕組み(外部情報を集め、業務判断の候補などに活用するもの)でも、AIの推奨と人間の承認を、次のように別々の記録として残しています。
- AIが候補を評価して「この案は使えそう」と推した記録
- 人間がまだ確認していない(保留中)とい�う記録
- 人間が活用へGOを出した記録
ポイントは、AIが推した記録があっても、それだけでは承認済みには変わらないことです。AIの推奨と人間の承認を別の記録にしておくと、「AIは推しているが、最終承認はまだ誰も出していない」という状態がそのまま残り、後から責任の所在を追うときに効いてきます。
freeeの事例でも、AIコーディングエージェント(Devin)が書いたコード変更(PR)を、そのAI自身が承認(Approve)できてしまう危険性が挙げられています。これは、コードを書く役割と承認する役割が同じ手元に混ざってしまう問題です。同社は必ず2人以上のApproveが必要になるよう改善し、書く側と承認する側を切り離したとされています。
賢さではなく「分業・承認・記憶」の設計が必要
ここまで挙げた問題は、一見バラバラに見えても根は一つです。AIの賢さが足りないのではなく、複数のAIを連携させる設計が足りていない。だから、個々のAIがどれだけ賢くなっても、連携のルールがなければ同じ問題は残��ります。デジタル庁の議論でも、複数AIシステムの連携では相互作用の管理が課題として扱われています。
5つの症状は、それぞれ次の設計が足りないことの表れと考えると整理できます。
| AIの連携で起きる問題 | 不足している設計 | 最初に見る対策 |
|---|---|---|
| 出力の受け渡しが合わない | 分業 | 入出力の形式を決める |
| 作業の重複・矛盾 | レビューと記憶 | 進捗を共有する状態を持つ |
| 重要な確認の抜け | 承認と権限 | 不可逆操作の前に承認点を置く |
| 停止箇所が分からない | 観測性 | 各工程のログを残す |
| 責任の所在が不明 | 観測性 | 誰の出力かを追える記録を残す |
これらの設計は、大きく「分業」「承認」「記憶」の3つにまとめられます。担当範囲を決める分業、リスクに応じて確認点を置く承認、そして作業状況やログを残して後から追える状態にする記憶です。レビューや観測性は、この記憶(何を共有し、何を記録しておくか)の一部だと考えると整理しやすくなります。
この「記憶」は、抽象的な良し悪しではなく、後から比較できる材料を残せるかどうかで効いてきます。前述のhermesでも、工程ごとの処理にかかった時間やどのモデルを使ったかをログとして残すようにしたところ、使うモデルやプロバイダによって処理時間が10倍近く変わることが分かりました。重要なのは差そのものより、それを事前の推測ではなくログで把握できたことです。各工程の記録を残しておくと、問題が起きてからではなく、平常時から「次�にどこを直すか」を判断しやすくなります。
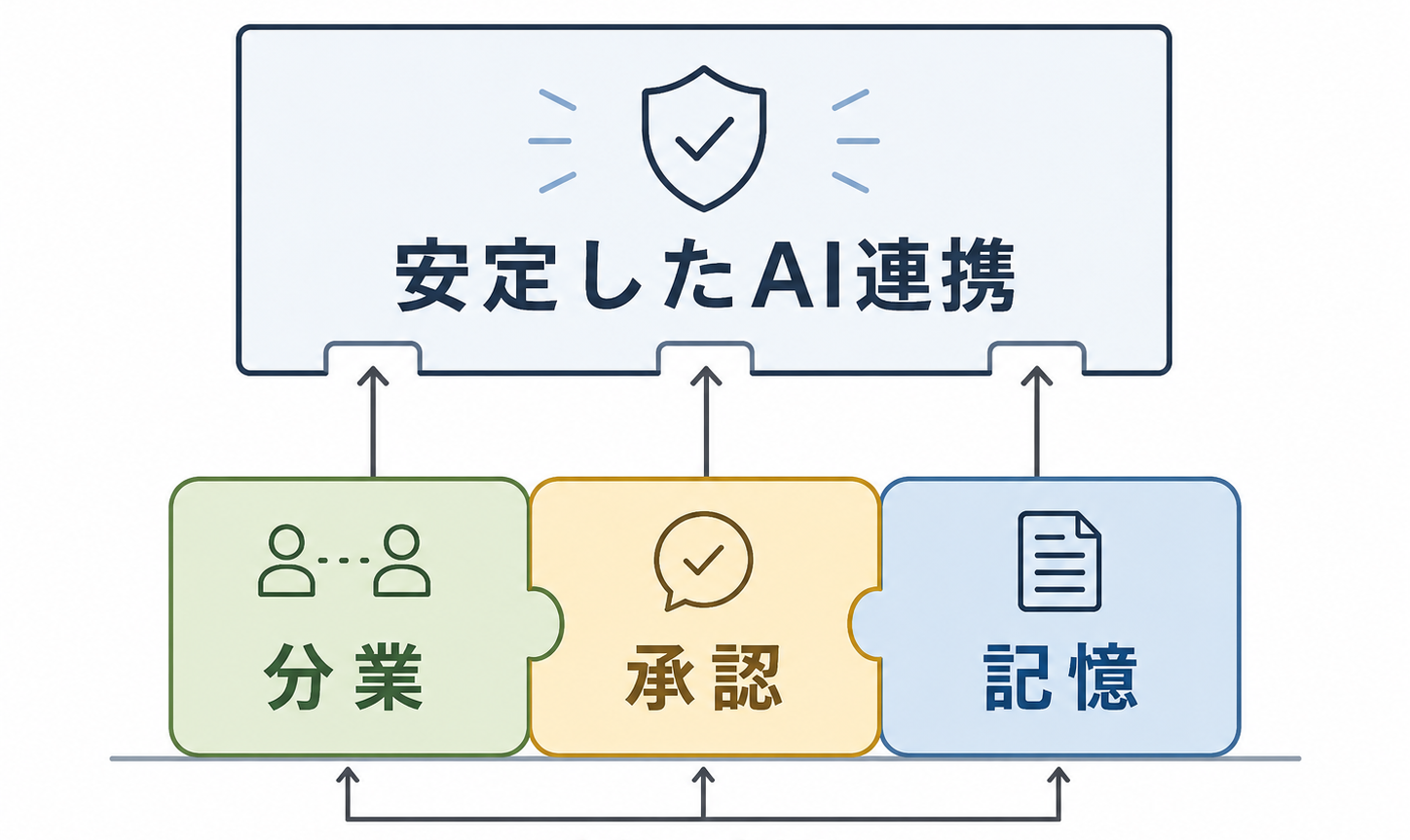
「分業」「承認」「記憶」のいずれも、個々のAIを賢くすれば解決する話ではなく、AI同士をどう束ねるかという設計の問題です。
AWSの解説でも、役割分担・共有情報・実行履歴は複数エージェントの協調に必要な要素として整理されています。実証面でも、マルチエージェントの失敗要因を分析した研究は、多くの失敗が個々のモデル能力よりも設計や協調の問題から生じると報告しています。
人間が介在する場所を意図的に作る
設計の中でも特に効くのが、重要な判断点で人間が承認・介入する仕組み(Human-in-the-loop)です。Google Cloudの資料でも、AIの提��案を人間が一度確認してから次の工程に進める設計が示されています。
ただし、すべての操作に同じ承認を付ければよいわけではありません。資料の要約のように戻しやすい処理は自動化し、顧客通知や本番データ更新のように戻しにくい操作にこそ人間の確認点を置く。リスクの大きさに応じて介在点を選ぶのが現実的です。
承認を増やしすぎると、かえって一つひとつの確認が形だけになる「承認疲れ」も起こります(Anthropicの運用でも、承認率が高止まりするapproval fatigueが報告されています)。確認の量ではなく、置き場所を設計する。ここでも判断軸は「体数」ではなく「戻しにくい操作がどこにあるか」です。会計やメールなど1つのツールで、どの操作を自動にしてどこで人間が確認するかという具体的な線引きは、別記事「AIエージェントに業務ツールをどこまで任せるか」で扱っています。
AIエージェントを組織化するには
組織化に向けた最初の作業は、AI間の受け渡しと確認の流れを見えるようにすることです。現状の業務プロ��セスで、どのAIの出力が次のどこへ渡り、どこで人間が確認しているのかを明らかにするところから始めます。
複数のAIツールを業務で断片的に使い始めている状況であれば、まずツール間の情報の流れや確認プロセスを図やリストに書き出して可視化してみるのが有効です。どのAIが何を出力し、それを誰が(またはどのAIが)受け取るのか。そして、どのタイミングで人間が確認しているのかを把握していきます。この段階で完璧な図を目指す必要はなく、課題になりそうな連携箇所をチームで共有することが目的です。
最後に: AIエージェント数より、戻せない操作とAI間の受け渡しを見る
AIエージェントを複数使い始めると、個々の能力だけでは解決しにくい、出力の受け渡しや確認をめぐる問題が生まれがちです。
ただし、組織化を始めるタイミングは、3体や5体といった体数だけでは決まりません。本番データの更新、外部送信、会計や契約の登録のように、戻しにくい操作が入るなら、少数のAIでも承認点とログを設計する価値があります。
そもそも、これは新しい問題ではありません。誰が担当し、誰が承認し、どう引き継ぐか。人間の組織が昔から壊れてきた理由と、その避け方を、私たちはすでに知っています。AIを増やすとは、小さな組織を一つ作ることであり、組織を機能させる原則は、相手がAIでも変わりません。
組織化を難しく考える前に、いま動かしているAIの連携の中で、「やり直しがきかない操作��」はどれかを決めます。その一点の手前に、人間の確認を一つ置く。賢いモデルを探すことでも、立派なフレームワークを導入することでもなく、組織化はそこから始まります。
本記事では、AIエージェントの数が増えると、なぜ「組織化」の設計が必要になるのかを解説しました。問題の根源は個々のAIの性能だけではなく、それらを協調させるための分業、承認、記憶といった、AI同士の受け渡しを支える設計が不足している点にあります。判断の起点は、AIの体数ではなく、不可逆操作や権限境界がどこにあるかです。
よくある質問
- 1体のAIエージェントでうまくいっている場合でも、組織化は必要?
- 単体で完結する業務なら、無理に複数化する必要はありません。重要なのは体数ではなく、元に戻しにくい操作、権限境界を越える処理、複数の受け渡しが入るかどうかです。そうした条件が出てきたら、少数のAIでも役割、承認、ログの設計を始めるタイミングです。
- マルチエージェントとAIエージェントの組織化は同じ意味?
- 近い概念ですが、この記事では少し広く扱っています。マルチエージェントは複数のAIを連携させる構成を指すことが多く、組織化はそこに役割分担、情報の受け渡し、人間の承認、責任範囲の整理まで含めた実務上の設計を指します。
- 人間の確認(Human-in-the-loop)を入れると、自動化の効果は落ちる?
- すべての工程に人間確認を入れると効率は落ち、承認そのものが形だけになりやすくなります。高リスクは人間承認、中リスクは管理者承認、低リスクは自動処理のように、承認の量ではなく�置き場所を設計する考え方が現実的です。
- 最初に整理すべきことは?
- まず、どのAIが何を出力し、その出力を誰またはどのAIが受け取るのかを書き出してください。次に、どの操作に人間の確認が必要か、失敗したときにどのログを見れば原因を追えるかを整理します。最初から高度なフレームワークを選ぶより、AI間の受け渡しと確認の流れを可視化することから始める方が進めやすくなります。
更新履歴(最終更新: 2026年6月4日)
- 初回公開
著者プロフィール
大崎 一徳 / エンジニア
中小企業向けに、AI導入・業務自動化・ツール開発を支援しています。 PoC から本番運用まで一貫して伴走し、「現場で使われ続ける仕組み」をつくることを大切にしています。
Udacity Deep Learning Nanodegree 修了
日本ディープラーニング協会(JDLA)主催 第1回ハッカソン GPU Eater賞受賞(チーム ニューラルポケット)
関連ガイド

AIエージェントに業務ツールをどこまで任せるか
AIエージェントに会計・メール・決済などの業務ツールをどこまで任せるか。権限、人間確認、監査ログの線引きを実務目線で整理します。

本番ログからLLM回帰テスト用データセットを作る最小構成|収集からCI接続まで
LLM/エージェントの本番ログから失敗ケースを自動抽出し、回帰テスト用の評価データセットへ変換してCIゲートに接続する最小構成を、収集・抽出・正規化・ラベリング・データセット化・CI接続の6ステップで解説します。

LLM/RAGの回帰テストをCIに組み込む設計ガイド:評価セットから運用レポートまで
プロンプト変更やモデル更新でRAGの回答が壊れる問題を、評価設計→回帰テスト→CIゲート→運用の型として固定。日本語の評価セットや回帰レポートの考え方も解説します。


