
Claude Sonnet/Opus 4.6 移行で本番を落とさないためのチェックリスト
Claude Sonnet 4.6 / Opus 4.6 がリリースされました。モデルを差し替えれば性能が上がる——そう思っていると、本番で思わぬ障害に遭うかもしれません。
今回の更新、気をつけておきたいのは「APIの動作前提が変わった」ことです。
- assistant prefill が 400 エラーで即死 — JSON出力の強制に使っていた定番パターンが動かない
- effort 未指定で思考コストが跳ねる — Sonnet 4.6 のデフォルトは high、レイテンシとコストが増加
- 20万トークン境界で割増課金 — 境界をわずかに超えるとリクエスト全体がプレミアム料金
どれも「deprecated はまだ動くが、ある日消える」類の問題です。放置すると、互換性破壊・コスト逸脱・品質ドリフトが本番で重なって出てくるかもしれません。
この記事では、壊れる前にやっておくべき差分を4領域に分けて整理します:
- effort — thinking の制御方法を切り替える
- 構造化出力 — prefill 廃止の受け皿を用意する
- 100万トークンコンテキスト / コンパクション β — 長文脈の扱いを決める
- ストリーミング・リトライ — 運用設計を固める
移行前に押さえておきたいこと
モデルを差し替えるだけでは済まない理由
チェックリストに入る前に、まず「モデル更新で何が変わるのか?」を整理します。
Claude Sonnet 4.6 / Claude Opus 4.6 への更新は、性能向上だけの話ではありません。API形状・課金境界・運用条件といった「呼び出し側の前提」も変わります。たとえば、これまで使えていた assistant メッセージの prefill(末尾 assistant ターンの先頭固定)は 4.6 世代ではサポートされておらず、リクエストが 400 エラーになります。
つまり、モデルを差し替えるだけでは済まず、API呼び出し側のコード・パラメータ・エラーハンドリングまで影響範囲が広がります。この記事では、そうした変更点を整理するところから始めていきます。
追随が遅れると壊れる4パターン
移行対応が遅れると、具体的にどのような問題が起きるのでしょうか。4つのパターンに分けて整理します。
互換性破壊(400エラー):deprecated になったパラメータや廃止された機能をそのまま送ると、APIがリクエストを拒否します。prefill 廃止はその典型例です。
タイムアウト:Claude Opus 4.6 は最大出力 12.8万 トークン、Sonnet 4.6 は最大 6.4万 トークンをサポートしています。出力が大きくなる分、ストリーミングなしの同期呼び出しではタイムアウトが起きやすくなります。
コスト逸脱:100万 コンテキスト β や thinking トークンの課金構造を把握しないまま移行すると、想定外のコスト増につながることがあります。
品質ドリフト:モデルの挙動変化により、既存のプロンプトやスキーマで期待どおりの出力が得られなくなることがあります。テストなしで切り替えると、本番で初めて気づく事態になりがちです。
この4パターンを意識しておくと、破壊的変更を整理するとき何を優先するかが見えてきます。
まず差分を整理:破壊的変更とDeprecated
切替当日に 400 が急増するのは、きっと prefill か旧パラメータの残骸でしょう。チェックリストについて見る前に、Claude 4.6世代で「今すぐ壊れる変更」と「猶予付きで将来壊れる非推奨」を整理しておきます。
prefill廃止:400エラーの原因と置換パターン
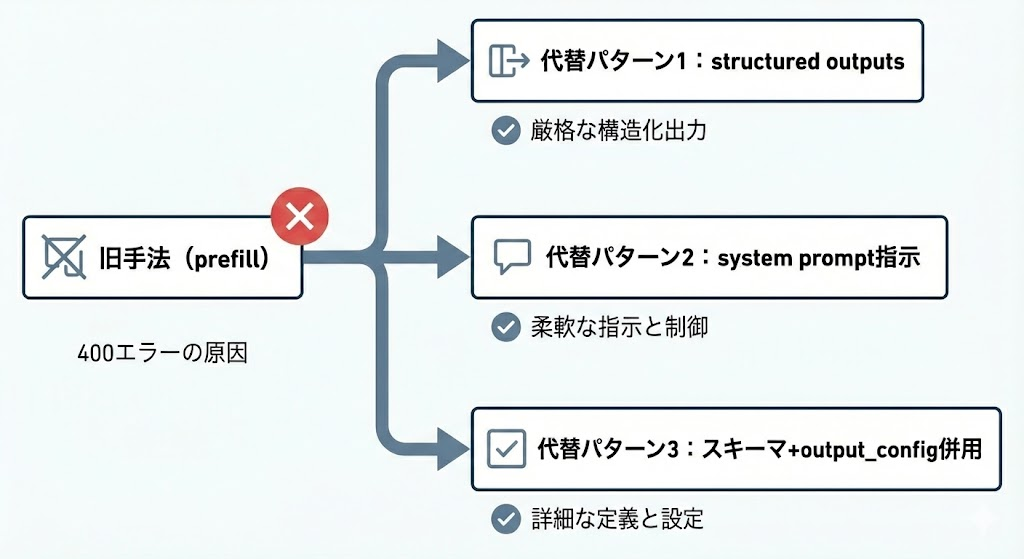
Claude 4.6世代で最も影響範囲が広い破壊的変更は、assistantメッセージのprefillが使えなくなった点です(末尾のassistantターン冒頭を固定する手法)。prefillはJSON出力の開始トークンを {"result": のように強制する用途で広く使われてきましたが、4.6世代�ではAPIレベルで非サポートとなり、prefillを含むリクエストを送ると400エラーが返ります。
従来のprefillが担っていた「出力形式の固定」は、主に3つのパターンで代替できます:
- 構造化出力(output_config.format)への移行 — JSONスキーマを指定すれば、prefillなしでも出力形式がスキーマに従う
- システムプロンプトでの出力指示 — 「応答は必ずJSON形式で返す」のような指示をシステムメッセージに含める。厳密なスキーマ制約が不要なケース向け
- 構造化出力のスキーマ定義と output_config.format の組み合わせ — prefillが担っていた出力制御をほぼカバーできる
もう1点気をつけたいのが、prefillで「思考の方向づけ」をしていたケースです。
たとえば {"analysis": で分析モードに誘導していた場合、システムプロンプトやユーザープロンプトでの明示的な指示に書き換える必要があります。出力形式の固定とは性質が異なるため、置換パターンを分けて検討しておくのが安全です。
ツール引数のJSONエスケープと末尾改行の差分
ツール呼び出しの引数パースが壊れる原因も押さえておきましょう。Claude 4.6ではツール呼び出し引数のJSONエスケープ(Unicodeエスケープやスラッシュのエスケープ有無)が従来モデルとわずかに異なることがあります。
文字列比較や正規表現で引数を自前パースしているコードは破綻しうるため、標準JSONパーサ(json.loads / JSON.parse 等)での解析に統一しておくのが安全です。
なぜ揺れるのか: モデルが生成するJSONの表現(/ を \/ にエスケープするか、末尾に改行が入るか、など)はモデルバージョンごとに変わりえます。仕様として固定されていない挙動に依存すると、モデル更新のたびに壊れるリスクがあります。
SDKを使っている場合: SDK内部でJSONパースが行われるため、この差分の影響を受けにくいことが多いです。ただし、SDKのレスポンスを文字列として加工してから再パースしている実装では、同じ問題が起きることがあります。
非推奨パラメータの一覧と削除タイムライン
「deprecatedはまだ動くが、ある日消える」——この認識が差分整理の出発点です。以下のパラメータ・ヘッダーは移行期間中は動作しますが、将来のAPIバージョンで削除される予定となって�います。
- budget_tokens → thinking.type: "adaptive" + effort に移行。effort値(low/medium/high/max)で制御
- output_format → output_config.format に移行。旧βヘッダー structured-outputs-2025-11-13 も不要に
- 旧βヘッダー群 → 正規パラメータに統合。effort関連、fine-grained-tool-streaming、interleaved-thinking 等
削除タイムライン: 公式に明示されていない項目もあります。「動いているから大丈夫」ではなく、移行先が確定している項目から計画的に差分を潰していくのが現実的です。放置すると、将来の障害として突然顕在化するリスクがあります。
差分整理の進め方:非推奨パラメータを洗い出して置換する
実務で差分を潰す手順は以下のとおりです。対象は4領域:
- APIクライアントコード
- SDKラッパー
- 設定ファイル
- CI/CDパイプライン
流れとしては、以下の3ステップが基本になります:
- grep(またはripgrep)で使用箇所を洗い出す
- 置換する
- 契約テストで固定する
それぞれのステップを具体的に見ていきます。
ステップ1:洗い出し — コードベース全体で以下のパターンを検索し、ヒットした箇所をリスト化します:
- budget_tokens
- output_format
- prefill 相当のパターン
- 旧βヘッダー文字列
ステップ2:置換 — 前述の置換パターンに沿って書き換えます。
ステップ3:契約テ��スト — APIレスポンスの形状(ステータスコード、レスポンスボディのキー構造、stop_reason)を検証するテストを追加しておくと、次回のモデル更新時にも同じ手順で差分検知ができます。
なお、設定ファイルや環境変数に埋まっているパラメータはgrepで拾いにくいことがあります。Terraformやクラウド設定(Bedrock等)経由で指定している場合は、インフラ側の設定も対象に含めておくのが漏れにくい進め方です。
チェックリスト1:thinking/effort — 思考量の制御方法を切り替える
破壊的変更の整理が済んだら、最初のチェックリストとして budget_tokens から effort パラメータへの切り替えで「何が変わり、何を確認するか」を確認していきます。
adaptive thinking と effort:それぞれ何を制御するか
Claude 4.6世代の thinking 設定では「モデルの思考量をどう制御するか」がポイントになります。
従来の thinking: {type:"enabled", budget_tokens:N} はトークン数を直接指定する方式でした。4.6世代ではこの方式が非推奨となり、代わりに adaptive thinking(thinking: {type:"adaptive"})と effort パラメータの組み合わせが推奨されています。
adaptive thinking と effort は別々の役割を持っています。adaptive thinking はクエリの複雑度に応じて思考量を動的に調整する仕組みで、「考えるかどうか・どれだけ考えるか」をモデル側が判断します。effort はその判断の深度ガイドとして機能し、高く設定すれば思考が深くなり、低く設定すればスキップされやすくなります。
budget_tokens は当面受理されるものの、将来削除予定です。「動いているから放置」ではなく、計画的に effort へ移行しておくのが安心です。
effort値の選び方:low/medium/high/maxの使い分け
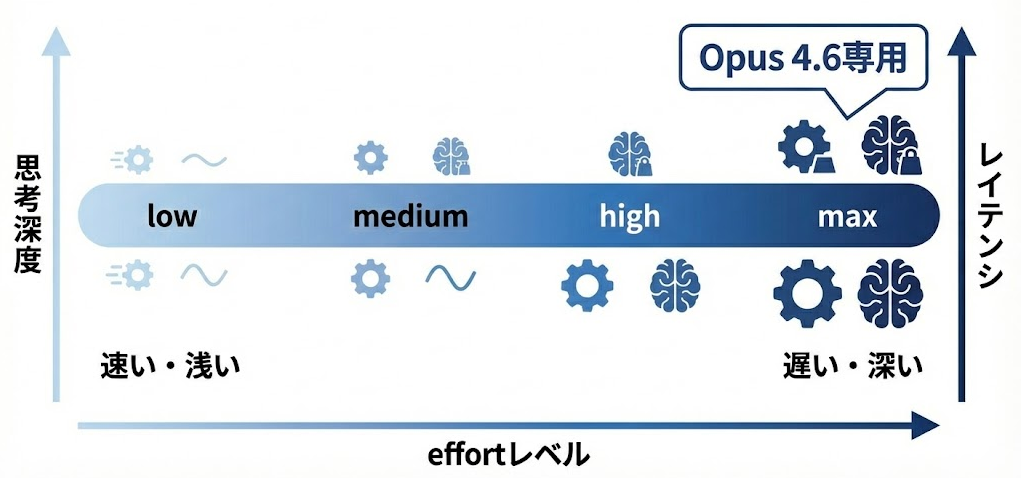
effort の各レベルで「モデルがどう振る舞うか」を把握しておくと、ユースケースごとの起点が決めやすくなります。
起点は用途の応答速度要件で決めると迷いにくくなります。
- low — thinking がスキップされやすく、分類・ルーティング・単純抽出など低レイテンシが求められる処理に向いています
- medium — 標準的なチャットや要約タスクで、思考コストと応答速度のバランスを取りたい場面が対象です
- high — 複雑な推論やコード生成など、精度を優先したいケースの起点になります
- max — Claude Opus 4.6 専用で、最大限の思考リソースを割り当てます。Sonnet 4.6 では指定できない点に注意が必要です
まず想定ユースケースで medium か high を起点に設定し、レイテンシと出力品質を計測したうえで上下に調整していく流れがスムーズです。effort パラメータは βヘッダー不要で一般提供されているため、既存コードへの追加も最小限で済みます。
移行時の落とし穴:デフォルトeffortとレイテンシ
「モデルを差し替えたらレイテンシが倍になった」——そんなときは effort の設定から確認すると良いでしょう。移行直後にレイテンシやコストが想定外に増える原因として多いのが「effort 未指定」です。
Claude Sonnet 4.6 は effort を明示しない場合のデフォルトが high に設定されています。従来モデルから単純に差し替えると、thinking が深く走る分だけレイテンシとトークン消費が増えることがあります。(移行ガイド参照)
effort のデフォルト high はモデルの能力を引き出す方向に振られた設定ですが、分類や定型抽出のように速度重視のエンドポイントで��は過剰になりがちです。
移行時にはすべてのエンドポイントで effort を明示的に設定しておくのが安全です。「とりあえず動かしてから調整」ではなく、既存の応答時間 SLA と照らし合わせて effort の起点を決めておくと、移行後の手戻りを減らせるかもしれません。
thinkingトークンの課金とレート制限への影響
effort 移行と合わせて確認しておきたいのが「thinking トークンはどこに計上されるか」という点です。
thinking トークンは 出力トークン(output tokens)として課金対象になります。レート制限(OTPM: Output Tokens Per Minute)の計算にも含まれるため、effort を高く設定するほどレート制限に到達しやすくなります。
ここで押さえておきたい点が2つあります:
- thinking トークンの増加がコスト増とレート制限の両方に影響する — effort=high のエンドポイントが複数ある環境では、OTPM の消費ペース監視を推奨
- マルチターン会話で過去ターンの thinking ブロックが自動的に除外される — 過去ターンの thinking は再送されないため、会話が長くなっても thinking 分の入力トークンは累積しない
この仕組みを踏まえると、移行後の課金シミュレーションでは以下を計測しておくのが有効です。コスト見積もりの精度が上がります。
1リ�クエストあたりの thinking トークン量 × リクエスト数
チェックリスト2:構造化出力 — 出力形式の指定方法を切り替える
effort の移行と並行して進めることが多いのが 構造化出力 です。やることは3つ。
- パラメータを引っ越す — output_format → output_config.format へ書き換え、旧βヘッダーを削除
- スキーマ上限を確認する — strict ツール20個、optional 24個、union types 16個、コンパイル180秒
- stop_reason を監視する — end_turn 以外なら出力が途中で切れている
以下、それぞれの詳細と制約を確認していきます。
output_formatからoutput_config.formatへの書き換え
リクエストボディの output_format は output_config.format へ移動しています。旧βヘッダー structured-outputs-2025-11-13 と旧 output_format は移行期間中まだ動作しますが、移行先は output_config.format 一本です。
まずコードベースで output_format を grep し、該当箇所を output_config: { format: ... } の形へ書き換えます。同時に、リクエストヘッダーに structured-outputs-2025-11-13 が残っていれば削除しておきます。SDK経由の場合はSDKバージョンを上げれば新パラメータに対応していることが多いですが、独自ラッパーを挟んでいるならラッパー側の変換ロジックも確認が必要です。
移行期間中は旧パラメータでも動作しますが、deprecated なパラメータは予告なく廃止される可能性があります。余裕のあるうちに差分を潰しておくのが安心です。
スキーマ複雑性の上限と初回コンパイル遅延
構造化出力のスキーマはいくつかの上限に縛られています。
- strict モードのツール数:最大20
- optional パラメータの合計:最大24
- union types(anyOf や type 配列)を使うパラメータの合計:最大16
- コンパイルタイムアウト:180秒
構造化出力は内部でスキーマからグラマー(文法制約)をコンパイルしています。スキーマが複雑になるほどコンパイルに時間がかかり、初回リクエストでレイテンシが急増する原因になります。コンパイル結果はグラマーキャッシュとして24時間保持されるため、2回目��以降は高速になりますが、キャッシュが失効するタイミング(24時間経過やスキーマ変更)で再び遅延が発生します。
上限を超えた場合はAPIがエラーを返します。既存のスキーマが上限に近い場合は、ツール定義の分割やunion typesの整理を事前に検討しておくとよいでしょう。デプロイ直後の初回リクエストがタイムアウトしやすい環境では、ウォームアップリクエストを仕込む運用も考えられます。
stop_reason監視と不完全出力への対処
構造化出力 を有効にしていても、出力が max_tokens に到達すると途中で切れます。途中で切れたJSONはスキーマに合致しないため、パース時にエラーになります。
つまり、レスポンスの stop_reason を確認する仕組みが必須です。stop_reason が end_turn であればスキーマ通りの出力が完了しています。max_tokens になっている場合は出力が途中で打ち切られています。
stop_reason が max_tokens になっていたら、max_tokens の値を増やしてリトライするのが定石です。リトライ前に部分出力をログに残しておくと、どの程度の出力量で切れたかの傾向が見えてきます。恒常的に切れる場合はスキーマの出力サイズ見積もりを見直す必要があります。
プロバイダごとの差分と併用不可の組み合わせ
プロバイダ経由で構造化出力を使う場合の差分と、機能の併用制約も押さえておきます。
構造化出力はClaude APIとAmazon BedrockでGA(�正式リリース)、Microsoft Foundryではpublic betaとして提供されています。プロバイダごとに output_config.format の渡し方やサポート状況が異なるため、利用中のプロバイダの最新ドキュメントを確認するのが確実です。
併用不可の組み合わせ: Citations(引用機能)をユーザー提供ドキュメントで有効化した状態で output_config.format(または旧 output_format)を併用すると、APIが400エラーを返します。引用機能は引用ブロックのインターリーブが必要であり、厳密なJSONスキーマ制約と構造的に両立しないためです。
Citations と 構造化出力 の両方が必要なユースケースでは、リクエストを分割する(まず引用付きで回答を取得し、別リクエストで構造化する)といった設計が考えられます。環境依存の組み合わせが多いため、利用する機能の組み合わせを事前にテストしておくのが安全です。
監視で見るなら stop_reason(end_turn 以外は出力途中切れ)と、初回リクエストの遅延(スキーマ変更後やキャッシュ失効後に急増する)。この2点を押さえておけば、構造化出力 周りのトラブルシュートは大半カバーできます。
チェックリスト3:100万トークンコンテキスト β / コンパクション β — 長文脈の扱いを決める
100万トークンコンテキストとコンパクションはどちらもβ機能です。提供条件や課金が変わることがあるため、段階導入とロールバックを前提に検討するのが安全です。「結局、使うべきか?」の判断は環境や要件次第ですが、参考までに判断目安を挙げておきます。
- 20万未満で回っているなら → まず使わない。GA範囲で十分
- 20万超が常態化しているなら → 100万トークンコンテキスト β を検討。ただし割増料金(入力2倍・出力1.5倍)を織り込む
- 会話が長期化してコンテキストが溢れるなら → コンパクション β を検討。ただし要約ドリフトと監査証跡の課題を許容できるか確認
判断に必要な3指標は 入力トークン数の分布(20万境界をどれだけ超えるか)、コスト増加率(プレミアム課金の影響)、失敗率・レイテンシ(β特有の不安定さ)。これらを staging で計測してから導入可否を決めます。
以下、それぞれの利用条件・制約・運用リスクを確認していきます。
100万トークンコンテキスト βの利用条件とβヘッダー
ここからは利用条件の詳細です。長文脈100万トークンを使える条件をまとめます。
100万 token context windowは、Claude Opus 4.6およびClaude Sonnet 4.6(ほか一部Sonnet 4.x)で利用できますが、デフォルトでは有効になっていません。利用には2つの条件を満たす必要があります。
- APIリクエストにβヘッダー
anthropic-beta: context-1m-2025-08-07を付与する - アカウントがusage tier 4以上またはcustom rate limitsである
βヘッダーのバージョン文字列は将来変更される可能性があります。「β=将来変更あり」が大前提なので、ヘッダー値をハードコードせず設定ファイルやfeature flagで管理しておくと、変更時の対応がスムーズです。tier条件を満たさないアカウントではヘッダーを付けてもエラーになるため、導入前にtierの確認が欠かせません。
20万トークン境界の割増料金と監視設計
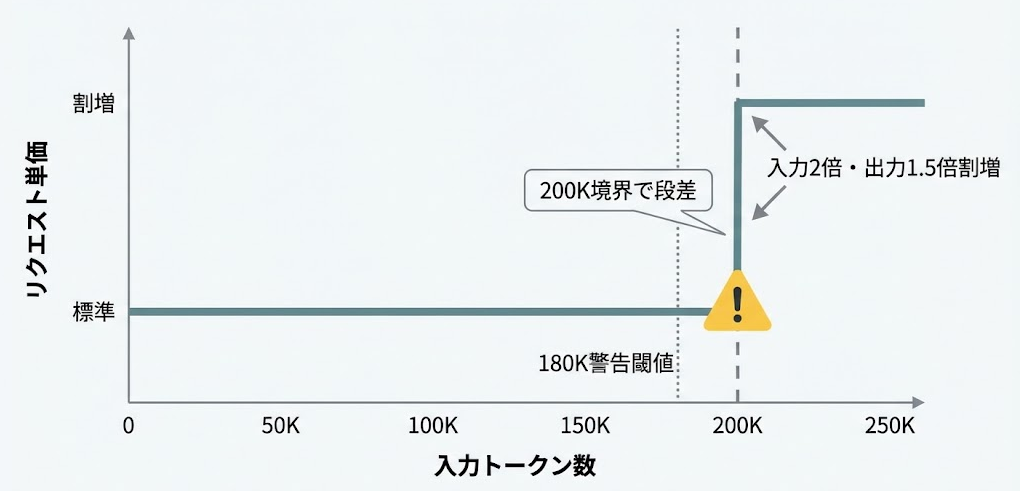
100万トークンコンテキストを有効にしたとき、コスト面で最も見落としやすいのが「20万トークン境界の割増料金」です。
通常の課金レートは20万トークン以下のリクエストに適用されます。20万を超えた瞬間、そのリクエスト全体がプレミアム料金の対象になります。入力は2倍、出力は1.5倍の課金です。境界を1トークンでも超えるとリクエスト全体に割増が適用されるため、「少しだけ超えた」ケースが最もコスト効率が悪くなります。キャッシュされたトークンを含むかどうかの判定ロジックも確認が必要です。
監視としては、APIレスポンスのusageオブジェクトで入力トークン数を取得し、20万付近のリクエストをアラート対象にする方法が考えられます。たとえば18万を警告閾値、20万を割増料金の閾値として2段階で監視すると、意図しない課金増を早期に検知できます。
長文脈リクエストには別のレート制限が適用される旨も公式ドキュメントに記載されています。コスト増だけでなくスループットの低下も想定して、負荷テスト時にプレミアム料金帯のリクエスト比率を計測しておくと安心です。β機能の課金体系は変更される可能性があるため、導入時点の公式ドキュメントで最新の数値を確認する運用が前提になります。
コンパクション βの仕組みと有効化手順
コンパクション βは「会話が長くなったときに、サーバー側でコンテキストを要約して圧縮する」機能です。
利用にはβヘッダー anthropic-beta: compact-2026-01-12 が必要です。Messages APIリクエストのパラメータに context_management.edits を追加し、typeとして compact_20260112 を指定します。
コンパクションが発動するデフォルトの閾値は150,000トークンです。最小値は50,000トークンまで下げられます。閾値を低くするほど要約が頻繁に走り、高くするほど生のコンテキストを長く保持できます。
コンパクション後も会話を継続する場合、圧縮されたコンテキストブロックがそのまま引き継がれます。βヘッダーのバージョン文字列が変わる可能性がある点は100万トークンコンテキストと同様で、設定は外出ししておくと変更時の対応が楽です。
コンパクションの運用リスク:要約ドリフト・監査・再現性
コンパクションを本番に入れる前に、知っておきたいリスクがあります。
要約ドリフト(情報損失): コンパクションは�サーバー側で要約を行うため、どの情報が残りどの情報が落ちるかを利用者側で完全には制御できません。会話のターンが長くなるほど、初期の文脈が要約で丸められるリスクが高まります。「要約されて困る情報はシステムプロンプトに持たせる」という設計判断が一つの対策です。
監査証跡の課題: コンパクション前後でコンテキストの内容が変わるため、「このレスポンスはどの入力に基づいて生成されたか」を厳密に再現することが難しくなります。監査要件が厳しい用途では、コンパクション前の完全な会話ログを別途保存しておく運用が考えられます。
コスト計測: usageオブジェクトのiterations情報を使って、コンパクションが走った回数やそれに伴うトークン消費を計測できます。コンパクション自体がAPIコールとして内部的に走るため、見かけ上のリクエスト数とコストが乖離することがあります。
再現性とsampling loops: server-side コンパクションとserver-side sampling loopsを併用する場合、要約タイミングとサンプリングの相互作用でレスポンスの再現性がさらに下がる可能性があります。テスト環境では「コンパクションをオフにした状態」をベースラインとして保持し、差分を計測する設計が安全です。
「deprecatedはまだ動くがある日消える」のと同様に、βは今は動くが仕様が変わる前提です。コンパクションの挙動変更がプロダクションに影響しないよう、feature flagでの制御が運用の基本線になります。
β機能の段階導入フロー:検証→導入→停止条件
100万トークンコンテキストとコンパクションをプロダクションに持ち込む際の段階導入フローを整理します。
前提: β機能は仕様変更リスクがあるため、20万コンテキスト(GA範囲)で動作するフォールバックパスを常に維持しておくことが前提です。
結論: 導入は3段階で進めると管理しやすくなります。
- 検証フェーズ: staging環境でβヘッダーを有効化し、代表的なユースケースで失敗率・レイテンシ・コストを計測します。20万以下のベースラインと比較できるデータを取得します
- 導入フェーズ: feature flagで一部トラフィック(たとえば5〜10%)にβ機能を適用し、本番負荷でのメトリクスを収集します。課金ジャンプやレート制限の実影響をこの段階で把握します
- 停止条件の定義: 失敗率がベースライン比でN%以上悪化、コストがM倍超過、p95レイテンシがX秒超過、再現性テストのpass率がY%以下——といった停止条件を事前に決めておき、閾値を超えたらflag offでフォールバックに戻します
停止条件の具体的な閾値は環境やSLA次第なので、ここで一般的な数値を示すことは避けます。重要なのは「閾値を決めずに導入しない」ことと、「flagを切ればGAの範囲に戻せる」状態を維持することです。
チェックリスト4:ストリーミング・リトライ・ロールバック — 運用設計を固める
API仕様とβ機能の差分を整理したあと、最後に確認したいのは「本番で長時間リクエストが失敗したとき、どう壊さずに回復するか」です。ストリーミング・リトライ・ロールバックの運用設計をまとめます。
ストリーミングを前提にする理由と設計指針
Claude Sonnet 4.6 世代では max_tokens を大きく取るユースケース(長文要約、コード生成、エージェントの多段出力など)が増えています。TypeScript SDK のデフォルトタイムアウトは10分ですが、非ストリーミングかつ max_tokens が大きい場合は最大60分程度まで動的に伸長されうるとされています。それでも、ネットワーク経路上のロードバランサやリバースプロキシが独自のタイムアウトを持つ環境では、SDK側の伸長だけでは救えないケースが出てきます。
長時間応答が想定されるリクエストは、ストリーミング(SSE)を前提にするのが安全です。ストリーミングでは最初のチャンクが届いた時点で HTTP 200 が返り、以降はイベントごとにデータが流れます。クライアント側でタイムアウトを「最終チャンク待ち」ではなく「チャンク間隔」で管理できるため、長大な出力でも接続が切れにくくなり��ます。
SSE では HTTP 200 のあとにエラーイベント(error や overloaded_error)が届く場合があります。ステータスコードだけで成否を判定する設計だと、部分出力だけ受け取って正常終了と誤認するリスクがあります。stop_reason が end_turn であることを確認するか、message_stop イベントの到達をもって完了判定とする設計が堅実です。
リトライ設計:SDKデフォルトとアプリ層の責任分界
Anthropic の TypeScript SDK は、接続エラー・408・409・429・5xx 等の一部エラーに対してデフォルトで2回リトライします。429 の場合は retry-after ヘッダーを尊重して待機します。
SDK のリトライとアプリ層のリトライを同時に有効にしていると、以下の計算式に従ってリクエストが発行される可能性があります。
SDKリトライ回数 × アプリリトライ回数 = �最大リクエスト数
最大リクエスト数が想定以上に膨らむと厄介です。レート制限に引っかかりやすくなるだけでなく、副作用のある処理(データベース書き込み、外部API呼び出し等)が重複実行されるリスクも出てきます。
こうした問題を避けるには、SDK層とアプリ層でリトライの責任を分けておくのが有効です:
- SDK 層: 一時的なネットワークエラーや 429/5xx に対する短期リトライを担当。SDK のデフォルト設定をそのまま使うか、maxRetries で回数を調整
- アプリ層: SDK が最終的にエラーを返したあとの判断を担当。リトライするか、フォールバック(旧モデルへの切り替え等)に回すか、ユーザーに通知するかを決めます
- 冪等性の確保: 同じリクエストが複数回実行されても結果が変わらない設計(リクエストIDによる重複排除など)を入れておくと、二重実行の影響を抑えられます
エラーが連続する状況に備えるなら、サーキットブレーカの導入も良いでしょう。連続エラーが閾値を超えたらリクエスト送信自体を一時停止し、バックエンドの回復を待つ仕組みです。ただし、閾値設定が厳しすぎると正常なリクエストまで止まるため、環境に合わせた調整が必要です。
レート制限・過負荷への対応(429/529)
Claude API のレート制限は利用ティアに依存し、RPM・ITPM・OTPM(リクエスト/分、入力トークン/分、出力トークン/分)の3指標で測定されます。いずれかを超えると 429 が返り、retry-after ヘッダーで待機時間が示されます。
429 は「自分のリクエスト量が上限を超えた」状態、529(overloaded_error)は「API側が一時的に混雑している」状態です。対処方針が異なるため、エラーコードで分岐しておくと対応しやすくなります。
429 への対処: retry-after ヘッダーの値だけ待ってからリトライすると良いでしょう。トラフィックが急増する場面(バッチ処理の開始時など)では段階的ランプアップ(最初は少量ずつ送り、徐々に増やす)で 429 の発生自体を抑える方法もあります。RPM/ITPM/OTPM のどの指標に引っかかっているかを把握しておくと、対策の精度が上がります。
529 への対処: API 側の負荷が原因のため、retry-after がない場合はエクスポネンシャルバックオフ(待機時間を指数的に延ばす)での再試行が有効です。長時間続く場合はサーキットブレーカで一時停止し、ユーザーへの通知やフォールバックに切り替える判断が必要になります。
Claude API の最大リクエストサイズは 32MB です。100万トークンコンテキスト β を使う場合、大量のコンテキストを送るとこの上限に近づくことがあるため、リクエストサイズの監視も入れておくと安心です。
ロールバック手順と押さえておきたい監視項目
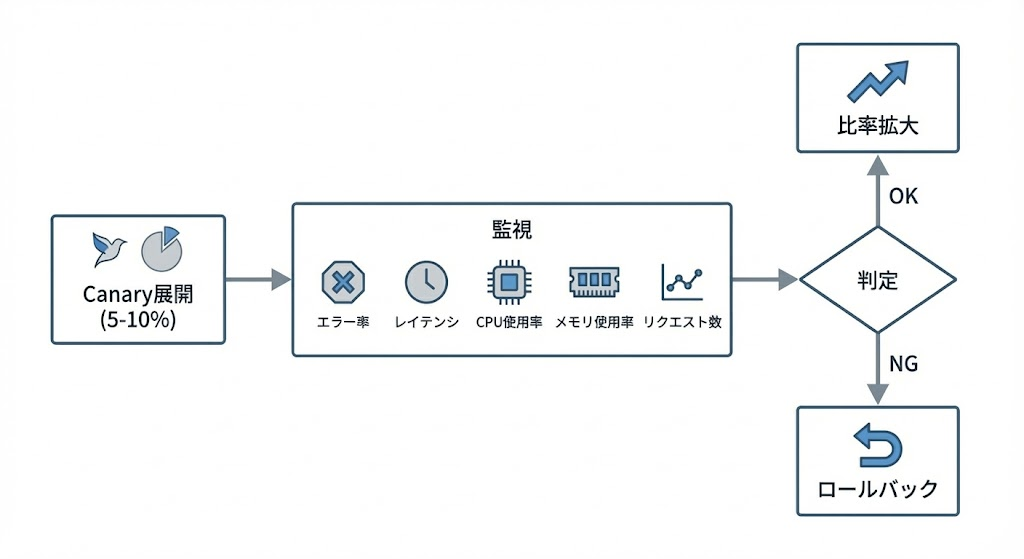
モデル更新の影響は、デプロイ直後ではなく数時間〜数日後に表面化することがあります(品質ドリフト、特定パターンでのレイテンシ悪化など)。ロールバックの速度は「モデルIDやパラメータが設定としてどこまで分離されているか」に依存します。
モデルID・effort値・max_tokens・βヘッダー等をコードにハードコードせず、環境変数や設定ファイル、feature flag で管理しておくと、コードデプロイなしでロールバックできます。
影響を早期に検知し、問題があればすぐに旧モデルへ戻せるようにするには、以下のような手順が有効です:
- canary 展開: トラフィックの5〜10%を新モデルに振り、残りは旧モデルのまま維持します。canary 期間中に異常が出なければ段階的に比率を上げていきます
- 押さえておきたい監視項目(この5項目をダッシュボードに出しておくと、異常の早期検知に役立ちます):
- request-id(問題発生時のトレーサビリティ)
- stop_reason(end_turn 以外の終了が増えていないか)
- usage オブジェクト(トークン消費量の変動)
- 429 発生率
- p95 レイテンシ
- 停止条件の事前定義: 「429率がN%を超えたら」「p95レイテンシがX秒を超え�たら」などの閾値を決めておき、超過時に自動または手動でロールバックを発動する運用が考えられます
壊れずに追随したいなら、API やSDKの差分を「仕様」として管理し、以下の流れを型にしておくとスムーズです:
- 変更検知
- 影響範囲の特定
- テスト
- ロールアウト
deprecated パラメータは「まだ動く」状態でも「ある日消える」前提で扱い、計画的に差分を潰していくと、将来の障害リスクを減らせるでしょう。
よくある質問
- prefillを使っていた場合、Claude 4.6での代替手段は?
- Claude 4.6世代ではprefillが非対応(400エラー)となります。JSON出力を強制したい場合は構造化出力(output_config.format)への移行が最有力です。それ以外のケースではシステムプロンプトやfew-shotでの例示への置き換えが基本方針です。詳しくは本文のチェックリストで確認できます。
- effortパラメータの初期値はどう決めればよい?
- Sonnet 4.6は未指定時のデフォルトがhigh(レイテンシ・コスト増)です。意図せぬコスト増を避けるためには effort を明示的に指定し、品質・コスト・レイテンシを計測しながら調整する段階的アプローチがおすすめです。
- output_formatからoutput_config.formatへの移行はいつまでに必要?
- output_formatは非推奨(deprecated)ステータスです。現時点で即座に停止されるわけではありませんが、新モデルでの動作保証がなくなる前にoutput_config.formatへ移行しておくのが安全です。
- 100万コンテキストβは誰でも使える?
- 100万βは特定のヘッダー指定が必要で、利用条件や課金体系が通常と異なる場合があります。最新の提供条件は公式ドキュメントで確認してください。
- コンパクションβは監査ログとして使ってよい?
- コンパクションは会話履歴の要約圧縮であり、要約ドリフトが起きることがあるため、監査目的での利用には注意が必要です。元の完全な会話ログを別途保持する設計をおすすめします。
- ストリーミング中にエラーが発生した場合の対処法は?
- 部分出力の扱い(破棄するか途中まで利用するか)をあらかじめ設計しておくことが重要です。リトライ時のべき等性と、タイムアウト閾値の設定をチェックリストで確認できます。
最後に
最後に、移行で失敗しないための3つのポイントをまとめます。
- prefill と旧パラメータを grep で洗い出す — 移行初日の 400 エラーはここから出る
- effort を明示する — 未指定だとデフォルト high でレイテンシとコストが増える
- β機能は flag で制御する — 仕様変更に備え、GA範囲へ即時フォールバックできる状態を保つ
まずはチェックリストを手元の実装と突き合わせて、対応順(今日やる/今週やる/後でいい)を仕分けるところから始めると進めやすいかもしれません。差分が大きく、統制点の設計レビューが必要な場合は 30〜60分のスポット相談もご利用ください。
更新履歴(最終更新: 2026年2月20日)
- 初回公開
著者プロフィール
大崎 一徳 / エンジニア
中小企業向けに、AI導入・業務自動化・ツール開発を支援しています。 PoC から本番運用まで一貫して伴走し、「現場で使われ続ける仕組み」をつくることを大切にしています。
Udacity Deep Learning Nanodegree 修了
日本ディープラーニング協会(JDLA)主催 第1回ハッカソン GPU Eater賞受賞(チーム ニューラルポケット)
関連ガイド

AIエージェントに業務ツールをどこまで任せるか
AIエージェントに会計・メール・決済などの業務ツールをどこまで任せるか。権限、人間確認、監査ログの線引きを実務目線で整理します。

AIエージェントが増えると壊れやすい理由:分業・承認・記憶で組織化する
AIエージェントを複数使い始めると、受け渡し、重複、確認漏れ、責任境界の問題が起きやすくなります。何体使うかではなく、分業・承認・記憶をどう設計するか、どの操作に人間の確認を残すかという視点で組織化を解説します。

本番ログからLLM回帰テスト用データセットを作る最小構成|収集からCI接続まで
LLM/エージェントの本番ログから失敗ケースを自動抽出し、回帰テスト用の評価データセットへ変換してCIゲートに接続する最小構成を、収集・抽出・正規化・ラベリング・データセット化・CI接続の6ステップで解説します。


